There is a lot of data out there in the internet. There are times you want to get at it. You may , for example, want the latest exchange rates, or maybe commodity prices. The problem in getting it is that you want it in a form that can be easily consumed and assimilated by SQL Server. We’ll show you how you might get an HTML table into a SQL Server table.
There often comes a time when one wants to parse an XHTML or HTML document into its DOM in order to get data from it. Without thinking too hard, we can think of several times we’ve wanted it.
- to get data from a table on an HTML page on the internet (with CURL.EXE it is so easy!)
- to make sure that an XHTML snippet is valid for a blog comment (e.g. has it got a TH or TD without an enclosing TR or TABLE?)
- to check if a snippet has got
SCRIPTin it? - to convert HTML code into IFcodes or BBcodes.
- to find all the anchors on an HTML page
- to index up existing HTML pages for site searches.
Occasionally, one can assign an XHTML snippet to an XML variable in SQL Server. We’ve never had much luck with this approach since perfectly valid XHTML can trigger an error in SQL Server’s XML.
There are several sensible approaches to investigating the Document Object Model (DOM) of an HTML document. These will generally involve scripting, using one of the existing DOM parsers. Parsing it using a stored procedure or function isn’t generally included in the list of sensible options.
You can, of course, use the Microsoft DOMDocument object, Microsoft.mshtml, the mozilla DOMparser, or the XMLDocument class in .NET. In PHP5 you would use the DOM extension. There are several other ways.
We’ll use TSQL.
Why do this? It is because we have a fine control over the results. We can get a table containing the DOM, in all its hierarchical glory, each row being a single element, in such a way that we can use SQL Queries to get whatever data we are interested in extracted.
One big problem with HTML is that browsers are deliberately tolerant of bad markup. This makes a robust way of analysing the structure of an HTML document extraordinarily elaborate. It is possible but the code is too long for a Workbench. Instead, we will provide the means to analyse the structure of an XHTML document or fragment. The difference here is that you are more likely to find that it is well-formed, and you can reject errors.
We’ve chosen to show you this as a stored procedure because this code is really is the stuff of workbenches. We’d like you to improve upon it and see if you can bend it to other purposes. Using a stored procedure rather than a function means that you can add debug code more easily whilst experimenting.
Don’t get us wrong. The code works well enough for the sort of jobs we have. XHTML without errors. (HTMLTidy is a wonderful app). We’d just be very pleased if you get interested in what we’ve done, and experiment with the ideas!
First off, we need a table with all the valid markup.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 |
--Creating the HTML Element table IF OBJECT_ID(N'HTMLTags') IS NOT NULL DROP TABLE HTMLTags--if it exists --don't try this technique in a live database with other users! --write the Tags/Elements table SELECT [tag]='!DOCTYPE', [meaning]='Defines the document type', [type]='Basic Tag',[HasclosingTag]=0 INTO HTMLTags UNION SELECT '!|[CDATA|[', 'delimits a javascript area in XHTML','Basic Tag',0 --note we have used the ESCAPE char | before the '[' character --as otherwise it would foul up the LIKE comparison UNION SELECT '?xml', 'flags an XML document','Basic Tag',0 UNION SELECT 'html', 'Defines a html document','Basic Tag',1 UNION SELECT 'body', 'Defines the body element','Basic Tag',1 UNION SELECT 'h1', 'Defines header 1 ','Basic Tag',1 UNION SELECT 'h2', 'Defines header 2 ','Basic Tag',1 UNION SELECT 'h3', 'Defines header 3 ','Basic Tag',1 UNION SELECT 'h4', 'Defines header 4 ','Basic Tag',1 UNION SELECT 'h5', 'Definess header 5 ','Basic Tag',1 UNION SELECT 'h6', 'Defines header 6 ','Basic Tag',1 UNION SELECT 'p', 'Defines a paragraph','Basic Tag',1 UNION SELECT 'br', 'Inserts a single line break','Basic Tag',0 UNION SELECT 'hr', 'Defines a horizontal rule','Basic Tag',0 UNION SELECT '!--', 'Defines a comment','Basic Tag',0 UNION SELECT 'b', 'Defines bold text','Char Format',1 UNION SELECT 'font', 'Defines the font face, size, and color of text', 'Char Format',1 UNION SELECT 'i', 'Defines italic text','Char Format',1 UNION SELECT 'em', 'Defines emphasized text ','Char Format',1 UNION SELECT 'big', 'Defines big text','Char Format',1 UNION SELECT 'strong', 'Defines strong text','Char Format',1 UNION SELECT 'small', 'Defines small text','Char Format',1 UNION SELECT 'sup', 'Defines superscripted text','Char Format',1 UNION SELECT 'sub', 'Defines subscripted text','Char Format',1 UNION SELECT 'bdo', 'Defines the direction of text display', 'Char Format',1 UNION SELECT 'u', 'Defines underlined text','Char Format',1 UNION SELECT 'pre', 'Defines preformatted text','Output',1 UNION SELECT 'code', 'Defines computer code text','Output',1 UNION SELECT 'tt', 'Defines teletype text','Output',1 UNION SELECT 'kbd', 'Defines keyboard text','Output',1 UNION SELECT 'dfn', 'Defines a definition term','Output',1 UNION SELECT 'var', 'Defines a variable','Output',1 UNION SELECT 'samp', 'Defines sample computer code','Output',1 UNION SELECT 'xmp', 'Deprecated. Use <pre> instead','Output',1 UNION SELECT 'acronym', 'Defines an acronym','Blocks',1 UNION SELECT 'abbr', 'Defines an abbreviation','Blocks',1 UNION SELECT 'address', 'Defines an address element','Blocks',1 UNION SELECT 'blockquote', 'Defines an long quotation','Blocks',1 UNION SELECT 'center', 'Defines centered text','Blocks',1 UNION SELECT 'q', 'Defines a short quotation','Blocks',1 UNION SELECT 'cite', 'Defines a citation','Blocks',1 UNION SELECT 'ins', 'Defines inserted text','Blocks',1 UNION SELECT 'del', 'Defines deleted text','Blocks',1 UNION SELECT 's', 'Defines strikethrough text','Blocks',1 UNION SELECT 'strike', 'Defines strikethrough text','Blocks',1 UNION SELECT 'a', 'Defines an anchor','Links',1 UNION SELECT 'link', 'Defines a resource reference','Links',0 UNION SELECT 'frame', 'Defines a sub window (a frame)','Frames',1 UNION SELECT 'frameset', 'Defines a set of frames','Frames',1 UNION SELECT 'noframes', 'Defines a noframe section','Frames',1 UNION SELECT 'iframe', 'Defines an inline sub window (frame)','Frames',1 UNION SELECT 'form', 'Defines a form ','Input',1 UNION SELECT 'input', 'Defines an input field','Input',0 UNION SELECT 'textarea', 'Defines a text area','Input',1 UNION SELECT 'button', 'Defines a push button','Input',1 UNION SELECT 'select', 'Defines a selectable list','Input',1 UNION SELECT 'optgroup', 'Defines an option group','Input',1 UNION SELECT 'option', 'Defines an item in a list box','Input',1 UNION SELECT 'label', 'Defines a label for a form control','Input',1 UNION SELECT 'fieldset', 'Defines a fieldset','Input',1 UNION SELECT 'legend', 'Defines a title in a fieldset','Input',1 UNION SELECT 'isindex', 'Deprecated. Use <input> instead','Input',1 UNION SELECT 'ul', 'Defines an unordered list','Lists',1 UNION SELECT 'ol', 'Defines an ordered list','Lists',1 UNION SELECT 'li', 'Defines a list item','Lists',1 UNION SELECT 'dir', 'Defines a directory list','Lists',1 UNION SELECT 'dl', 'Defines a definition list','Lists',1 UNION SELECT 'dt', 'Defines a definition term','Lists',1 UNION SELECT 'dd', 'Defines a definition description','Lists',1 UNION SELECT 'menu', 'Defines a menu list','Lists',1 UNION SELECT 'img', 'Defines an image','Images',0 UNION SELECT 'map', 'Defines an image map ','Images',1 UNION SELECT 'area', 'Defines an area inside an image map','Images',0 UNION SELECT 'table', 'Defines a table','Tables',1 UNION SELECT 'caption', 'Defines a table caption','Tables',1 UNION SELECT 'th', 'Defines a table header','Tables',1 UNION SELECT 'tr', 'Defines a table row','Tables',1 UNION SELECT 'td', 'Defines a table cell','Tables',1 UNION SELECT 'thead', 'Defines a table header','Tables',1 UNION SELECT 'tbody', 'Defines a table body','Tables',1 UNION SELECT 'tfoot', 'Defines a table footer','Tables',1 UNION SELECT 'col', 'Defines attributes for table columns ','Tables',0 UNION SELECT 'colgroup', 'Defines groups of table columns','Tables',1 UNION SELECT 'style', 'Defines a style definition','Styles',1 UNION SELECT 'div', 'Defines a section in a document','Styles',1 UNION SELECT 'span', 'Defines a section in a document','Styles',1 UNION SELECT 'head', 'Defines information about the document','Meta Info',1 UNION SELECT 'title', 'Defines the document title','Meta Info',1 UNION SELECT 'meta', 'Defines meta information','Meta Info',0 UNION SELECT 'base', 'Defines base URL for all links in a page','Meta Info',0 UNION SELECT 'basefont', 'Defines a base font','Meta Info',0 UNION SELECT 'script', 'Defines a script','Programming',1 UNION SELECT 'noscript', 'Defines a noscript section','Programming',1 UNION SELECT 'applet', 'Defines an applet','Programming',1 UNION SELECT 'object', 'Defines an embedded object','Programming',1 UNION SELECT 'param', 'Defines a parameter for an object','Programming',0 --we thought this was a rather useful list! GO |
The stored procedure spParseXHTML takes an XHTML fragment or document and returns a result that gives the list of tags, their nesting level, the order in which they were retrieved, the parameters, the innerHTML, the index into the document where the start of the tag was, the index into the document where the end of the tag was, and where the parent tag started. Finally, it has the key of the parent tag. This should be sufficient to do a fair amount of data analysis.
The stored procedure is iterative. It should be recursive, but SQL Server isn’t naturally recursive, so an iterative solution was used instead. It isn’t fast. A large XHTML page took, we found, around ten seconds to analyse – but then there was all that lovely data!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 |
--Creating the Parsing procedure IF OBJECT_ID(N'spParseXHTML') IS NOT NULL DROP PROCEDURE spParseXHTML GO CREATE PROCEDURE [dbo].[spParseXHTML] @Mydocument VARCHAR(MAX)--the XHTML document or fragment AS SET NOCOUNT ON DECLARE @TagParams VARCHAR(8000), @originalDocument VARCHAR(MAX),--copy of document @Beginning INT,--the point at which the search for tags starts @StartOfTag INT-- the opening < of the tag DECLARE @StartOfParentTag INT,-- the opening < of the parent tag @EndOfTag INT,-- the closing > of the tag @BackOfTag INT,-- the end > of the </tag> @ClosingTag INT,--the start < of the </tag> @nested INT,--is this tag nested @ii INT,--iteration counter (just in case!) @innerHTML VARCHAR(MAX),--the innerHTML between the tags @hAScLOSINGtAG INT,--does the tag has a closing tag? @Nesting INT,--the nesting count @Tag VARCHAR(20),--the current tag (e.g. input) @Error VARCHAR(8000)--the current error if any CREATE TABLE #dom--we create the table that holds our DOM info ( Element_ID INT IDENTITY(1, 1),--the unique identifer of each tag nesting INT,--the nesting level of the tag tag VARCHAR(20),--the actual tag (e.g. DIV, P, SPAN) tagparams VARCHAR(7800),--the parameters (e.g. class="blue") innerHTML VARCHAR(MAX),--the html code contained in the tag startOfTag INT,--the start < position of the <tag> EndOfTag INT,-- the end position of the > of the </tag> StartOfParentTag INT,--the start < position of the parent <tag> parent INT-- the key (Element_ID) of the parent tag (null if none) ) SELECT @ii = 1, @beginning = 1, @nesting = 0, @OriginalDocument=@MyDocument --initialise variables IF @MyDocument IS NULL --nothing to do OR LEN(@MyDocument) < 5 OR CHARINDEX('<', @MyDocument) = 0 SELECT @ii=10000--nothing to do but we must show empty table WHILE @Beginning < LEN(@MyDocument) AND @ii < 10000--for all the document... BEGIN --lets search for the next element SELECT @ii = @ii + 1--tally of iterations, in case something goes wrong. --so we find the next start of the initial tag and end of the initial tag SELECT @StartOfTag = CHARINDEX('<', @MyDocument, @Beginning - 1), @EndOfTag = CHARINDEX('>', @MyDocument, @Beginning) IF @EndOfTag = 0--all done, no end-tag found OR @StartOfTag = 0 --or start tag either! BREAK--because it has been finished IF @EndOfTag < @StartOfTag--probably random tag BEGIN--we take out the offending end-tag SELECT @MyDocument = STUFF(@MyDocument, @EndOfTag, 1, ']') SELECT @Error=COALESCE(@Error+', ','')+'Syntax anomaly at' +SUBSTRING(@MyDocument,@endOfTag+1,20) CONTINUE-- flag an error END --now we identify the tag from the table list we've prepared SELECT TOP 1 @HasClosingTag = HasClosingTag, @Tag=tag,@innerHTML='' FROM htmltags WHERE SUBSTRING(@MyDocument,@StartOfTag+1,20) LIKE tag+'%' ESCAPE '|' ORDER BY LEN (tag) DESC--the longest match IF @@rowcount = 0---if unrecognised or spurious end BEGIN --neutralise the tags. they seem to be in error! IF (SUBSTRING(@MyDocument,@StartOfTag+1,1)='/')--eek, end tag SELECT @Error=COALESCE(@Error+', ','') +'Missing opening tag for <'+SUBSTRING(@MyDocument,@StartOfTag+1,15) ELSE --a tag that isn't in our list SELECT @Error=COALESCE(@Error+', ','') +'Could not find tag at '+SUBSTRING(@MyDocument,@StartOfTag+1,20) --neutralise it so we never re-read it --and take out all the pesky '<' and '>' characters in the block SELECT @MyDocument = STUFF(@MyDocument, @EndOfTag, 1, 'X'), @MyDocument = STUFF(@MyDocument, @StartOfTag, 1, 'X'), @Beginning = 1 CONTINUE END IF @tag='!--'--the comment tag is a special case, blast it BEGIN SELECT @EndOfTag = CHARINDEX('-->', @MyDocument, @StartOfTag)+2 IF @EndOfTag=2--nothing found BEGIN SELECT @Error=COALESCE(@Error+', ','') +'Could not find end of comment''-->''', @EndOfTag=LEN(@MyDocument) END --and take out all the pesky '<' and '>' characters in the block SELECT @MyDocument = STUFF(@MyDocument, @StartOfTag, @EndOfTag-@StartOfTag, REPLACE(REPLACE( SUBSTRING(@MyDocument, @StartOfTag, @EndOfTag-@StartOfTag), '>',']'),'<','[')) END IF @tag='!|[CDATA|['--the CDATA tag is another special case, damn it BEGIN SELECT @EndOfTag = CHARINDEX(']]>', @MyDocument, @StartOfTag)+2 IF @EndOfTag=2 BEGIN SELECT @Error=COALESCE(@Error+', ','') +'Could not find end of CDATA block', @EndOfTag=LEN(@MyDocument) END SELECT @MyDocument = STUFF(@MyDocument, @StartOfTag, @EndOfTag-@StartOfTag, REPLACE(REPLACE( SUBSTRING(@MyDocument, @StartOfTag, @EndOfTag-@StartOfTag) ,'>',']'),'<','[')) END SELECT @tagparams = LTRIM(RTRIM(SUBSTRING(@MyDocument,@startOfTag+LEN(@Tag)+1, @EndOfTag-(@StartOfTag+LEN(@Tag)+1)))) IF @HasClosingTag <> 0 --it has a closing-tag (HTML often leaves this out) BEGIN--now we find the closing tag SELECT @closingtag = CHARINDEX('</' + @tag + '>', @MyDocument, @EndofTag), @nested = CHARINDEX('<', @MyDocument, @EndofTag) IF @nested = 0 --there is no closing tag so it cannot be legal BREAK --nowt else to do! IF @nested < @closingTag --Aha! that was nested! BEGIN--increment the nesting counter, and look for the first --child tag SELECT @Nesting = @nesting + 1, @beginning = @EndOfTag + 1, @StartOfParentTag=@StartOfTag CONTINUE END IF @ClosingTag = 0 BEGIN SELECT @Error=COALESCE(@Error+', ','') +'Could not find a matching </' + @tag + '>' SELECT @beginning = @endOfTag + 1 CONTINUE END --so now we neutralise all the < > characters in the tag so we --dont find the same tag again SELECT @MyDocument = STUFF(@MyDocument, @closingTag, 1, '[') SELECT @MyDocument = STUFF(@MyDocument, @closingTag+LEN(@tag)+2, 1, ']') SELECT @MyDocument = STUFF(@MyDocument, @EndOfTag, 1, ']') SELECT @MyDocument = STUFF(@MyDocument, @StartOfTag, 1, '[') --left as four select statements for clarity! SELECT @innerHTML = SUBSTRING(@OriginalDocument, @EndofTag + 1, @closingTag - @EndofTag - 1),--get the innerHTML @BackOfTag=@closingTag+LEN(@tag)+3 END ELSE--it was a tag without a closing tag (e.g. hr, br, input) BEGIN IF LEN(@TagParams)>0 IF SUBSTRING(REVERSE(@tagparams),1,1)='/' SELECT @TagParams=LTRIM(RTRIM(LEFT(@TagParams, LEN(@TagParams)-1) )) SELECT @MyDocument = STUFF(@MyDocument, @EndOfTag, 1, ']'), @BackOfTag=@endOfTag SELECT @MyDocument = STUFF(@MyDocument, @StartOfTag, 1, '[') END --now all we need to do is to record the Element in the table INSERT INTO #dom (nesting, innerHTML, tag, tagparams, StartOfParentTag, StartOfTag, EndOfTag) SELECT @nesting, @innerHTML, @tag, @Tagparams,@StartOfParentTag, @StartOfTag,@BackOfTag SELECT @Nesting = 0,@beginning = 1 END --end of the WHILE loop UPDATE #dom --now stitch in the keys to the parent tags and then all is done! SET parent = parentTag.Element_ID FROM #dom INNER JOIN #dom parentTag ON #dom.StartOfParentTag = parentTag.StartOfTag AND #dom.StartOfParentTag <> #dom.StartOfTag SELECT * FROM #dom IF @error IS NOT NULL--oops, an error. This should help clean up the XHTML BEGIN RAISERROR(@error,16,1) RETURN(1) END GO --Now, here is a small sample just to show you how to use it. We'll get data --out of a table (it is just as easy getting them from Anchors <a> or --divs. --Using the Parser CREATE TABLE #Ourdom ( Element_ID INT, nesting INT, tag VARCHAR(20), tagparams VARCHAR(7800), innerHTML VARCHAR(MAX), startOfTag INT, EndOfTag INT, StartOfParentTag INT, parent INT ) INSERT INTO #OurDom EXECUTE spParseXHTML ' <table class="data"> <tr style="vertical-align: bottom !important"> <th>Currency</th> <th>Weights based on<br> 1999-2001 trade data <sup>a</sup></th> <th>Weights based on<br> 1989-1991 trade data <sup>b</sup> </th> </tr> <tr> <td>U.S. dollar</td> <td>0.7618 </td> <td>0.5886</td> </tr> <tr> <td>Euro</td> <td>0.0931</td> <td>0.1943</td> </tr> <tr> <td>Japanese yen</td> <td>0.0527</td> <td>0.1279</td> </tr> <tr> <td>Chinese yuan</td> <td>0.0329</td> <td>—</td> </tr> <tr> <td>Mexican peso</td> <td>0.0324</td> <td>0.0217</td> </tr> <tr> <td>U.K. pound</td> <td>0.0271</td> <td>0.0368</td> </tr> <tr> <td>South Korean won</td> <td>—</td> <td>0.0307</td> </tr> </table>' |
This will give the following table (some TRs are omitted so that the image size is not too great).
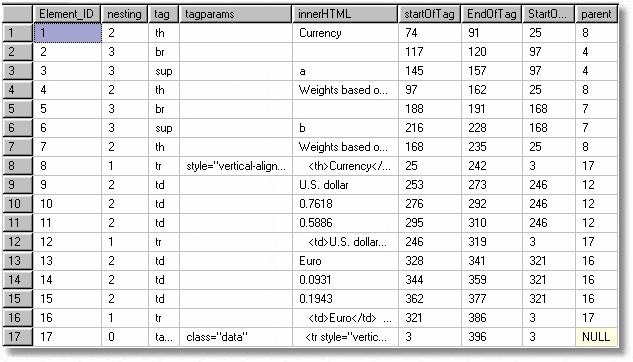
Now that we have our elements all in a table, we can take out just the data we want. Obviously, real data will usually have more information than this, but we didn’t want the workbench to become too unwieldy.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
SELECT [Currency]=MAX(CASE WHEN col=1 THEN contents ELSE '' END), [Weights (1999-2001)]=MAX(CASE WHEN col=2 THEN contents ELSE '' END), [Weights (1989-1991)]=MAX(CASE WHEN col=3 THEN contents ELSE '' END) -- with a bit more trouble, and some Dynamic SQL, we can pick out the -- THs and dynamically build the column names. But the code would not -- be so easy to read, so we sat on our hands! (Phil, the old showoff -- was dying to show how to do it. R.P.) (I may add it in a comment P.F.) FROM (SELECT parent,[contents]=innerHTML, [col]=( SELECT COUNT(*) FROM #ourdom siblings WHERE siblings.parent=dom.parent AND siblings.Element_ID<dom.Element_ID )+1 FROM #Ourdom dom WHERE parent IN (SELECT Element_ID FROM #Ourdom WHERE parent = (SELECT TOP 1 Element_ID FROM #Ourdom WHERE tag = 'table' ) AND tag = 'tr' ) AND tag = 'td' ) f GROUP BY parent ORDER BY parent GO DROP TABLE #OurDom /* Currency Weights (1999-2001) Weights (1989-1991) ----------------- -------------------- -------------------- U.S. dollar 0.7618 0.5886 Euro 0.0931 0.1943 Japanese yen 0.0527 0.1279 Chinese yuan 0.0329 — Mexican peso 0.0324 0.0217 U.K. pound 0.0271 0.0368 South Korean won — 0.0307 (7 row(s) affected) |
So there we are. The next stage is to get the pages directly from the website. If your SQL Server has direct access to the internet (behind a NAT and Firewall I hope) you can do this quite easily and we’ve already shown you how to do that in the past!
Maybe a future Workbench could give a few illustrations of ways of accessing pages on the internet.
Load comments