Data Governance: Joining the Dots
Every organization must perform data governance. This requires planning, oversight, and control over the management, security, resilience and quality of data and over the use of data by the organization. In larger organizations, it can be a complex task. William Brewer explains what's involved.
In a small organization, data governance sounds like a tranquil role. Why, for example, would one ever need a data discovery tool? How can there be any doubt about the source of data? How hard is it to document who can see what data and how?
In any organization there is entropy. All organizational structures, and the ways that they organize data, tend to decay, especially with high staff-turnover. However well data is originally organized, it eventually leaks everywhere within the organization because it is so easily copied. Its importance is, over time, misunderstood or misinterpreted. The processes that use the data are seldom properly documented, relying instead on ‘herd memory’. The data itself is often so badly documented that sometimes even units of measurement are misinterpreted.
What if some of the data in the organization has to be altered? It happens. Fine, one might think, just alter it in the source and allow correction to trickle downstream. Hmm: only if the source is known, for the data could have drifted from data store to file, to database, like smoke through a jungle. Such data is as immune from correction as internet gossip.
The effort involved in fighting this entropy can come to dominate the attention of the IT activity of an organization. This isn’t a quasi-mystical compulsion: changes in legislation, and the increasing sophistication of hacking will also affect existing data in existing ‘legacy’ systems.
The alternatives to data governance?
IT management can’t avoid the difficult task of data governance, in all its many aspects. Many have tried, but fate will always strike in unexpected ways.
You can’t avoid the fight against data entropy by clearing the old data out. Proper record keeping and data-retention are essential, especially in the case of litigation. I know of companies that saved millions by obsessively keeping old records, and many others who could have proved their defence had they only done active data retention and kept the evidence.
It also doesn’t end well if you ignore what the industry euphemistically describes as ‘legacy data’. I remember the surprise during an audit of finding that the entire department of a branch of Government was being run by a legacy application, running on a server under someone’s desk in the open-office area. It contained highly sensitive information, had never even been backed up, and was entirely unknown to the IT department who had just given me an effusive guided tour of their immaculate data center.
After many years of advising on data security, I retain a morbid fascination in reading of the prosecution and fines levied on companies who have accidentally ‘leaked’ sensitive or private information. Unsurprisingly, a plea of not knowing about the lack of data protection cuts no ice in a court of law. It is the duty of the board of a company to know what precautions are in place. Sometimes they aren’t in place. I once found a vendor-maintained database that was accessed remotely via an SA account with no password.
Aspects of data governance
It is surprisingly common to find IT managers who become dazzled by one or two aspects of data governance, to the point of believing that the others don’t matter. It is like building a castle gatehouse and forgetting the curtain walls and moat. When assessing the overall quality of data governance, all aspects are important. It is no use knowing where all the data is held if it leaks out. There is no point in encrypting data if you haven’t tackled access control. It is of little use to deduplicate data and be clear of the ultimate source of data if you haven’t planned for the eventuality of a major event such as an airliner crashing into your data center. And yes, this almost happened to a major retail bank; it just missed. There were major repercussions for disaster recovery planning.
Surveying and Mapping
The process of making sure that you know the location, purpose and origin of all your data is essential. If, for example, you know where all the personal data is, then you can very simply apply the same rule of curation to all of it, and you can report accurately to the board. If you know the origin of the data, you can correct it at source. Data, basically, becomes more manageable.
There are three main tasks involved in the surveying and mapping of your data:
- Data Discovery – knowing where and how the data is stored, and why.
- Data Mapping – identifying the source of all data, the paths by which it is processed, and its destinations
- Data Classification (or Modelling) – classifying data so that you understand its requirements for resilience and protection.
Unless you’ve worked for a large organization, especially one that’s been around for a while, you probably won’t appreciate just how complicated these tasks can get. However, it’s essential as much of the organization’s data strategy and policies, and standard for handling data will derive from this work.
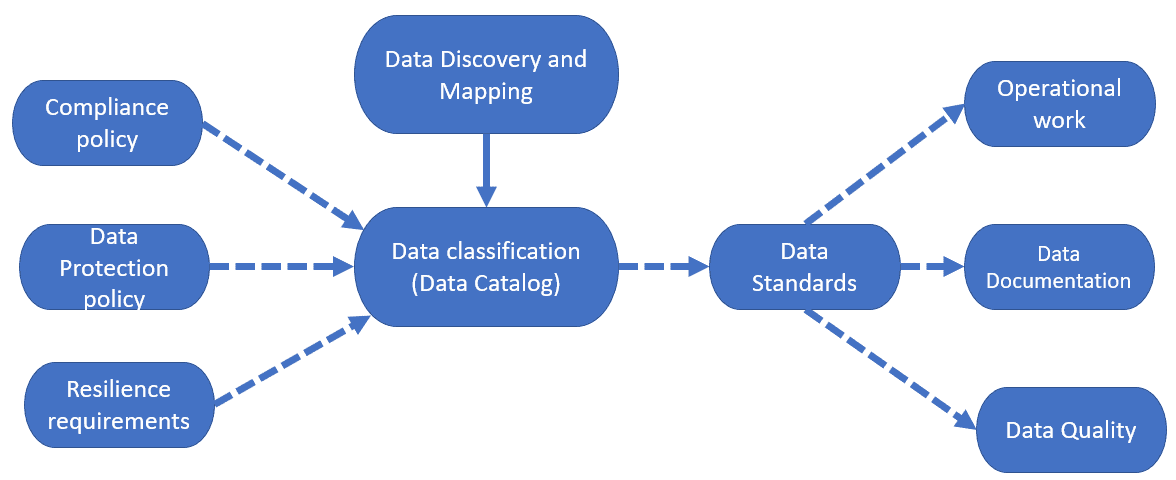
Data Discovery – where and how is the data is stored, and why?
So many activities require database-driven applications, and these applications tend to come and go with the enthusiasm of the management of that department. Even with the major corporate databases, it isn’t always obvious where data is held because the organization’s most important business functions would have been ‘re-engineered’ several times over the years.
A bank, for example, may keep the details of a single customer in several databases, so that a full report on a single customer can require several separate data accesses to different servers. Added to that is the complication of cloud storage, where a new data store can be set up with nothing more than a fat budget and an ignorance of the risks and repercussions.
Some organizations don’t even use databases for their core data, preferring various structured documents, lists or collections of spreadsheets. Others use databases in bizarre ways. For the data professionals, this is all outside their control; it just means that all the locations of data must be identified and mapped so that some of the other activities in this list can then be undertaken.
Data mapping – who uses the data, how, and in what order?
By mapping data, you are identifying the source, lineage (meaning the paths by which it is processed) and destinations of all data. I can best explain why this is important by way of an example. In one organization I worked for, there was a database on a server, in the server room. The server, a now-redundant mainframe, needed to be replaced, but nobody knew if anyone was using it. There wasn’t adequate record keeping or documentation. All enquiries failed, and nobody owned up to using it. It seemed to be getting little traffic, and what there was could easily have been an automated monitoring system. Eventually, the data center manager switched it off to see if anyone objected. The result was rather exciting, as an entire division of the organization temporarily ground to a halt, and there were several angry phone calls. Things calmed down when we pointed out how much we were owed for maintaining the system over the years.
Documenting data lineage is an aspect of mapping that means establishing all the ways in which data is used, transformed and consumed. Until we’ve done this, we can’t implement effective checks on other aspects of data governance such as data security, access control or network planning.
Data classification or modelling– what types of data do we handle?
We need to identify each class of data, its sensitivity, and its relative importance to the functioning of the organization.
By classifying the data, we determine the organizational rules that apply to the data and any special requirements for compliance. This implies that there are organization-wide rules for compliance. Establishing and maintaining the general rules is part of the general task of IT data governance, and you will not get the best value from mapping and surveying data until these rules have been adopted across the organization.
Data strategy and policy
The data discovery and classification activities will result in a data catalog with classification ‘tags’ indicating the various types of business or personal data. Each class of data will have an associated policy describing how that data will need to be managed, monitored and protected, and its required level of resilience.
Data accountancy – assessing the quality of data governance
Any IT department must keep the board of a company, or trustees of a charity, aware of the extent to which data within the organization is being managed, in accordance with the organization’s adopted standards. This is called Data Accountancy.
As part of this task, the manager must check the extent of data compliance, in other words that the organization is up to date with industry and legislative standards. This isn’t always an enviable task. To tell the bare truth, one risks the board members wishing you hadn’t told them, as if ignorance was a get-out, whereas if one gives too reassuring an account, one is likely to be faced with ‘Why didn’t you tell me that …?‘
Data protection – assessing the precautions taken by users of data
Data leaks out from surprising places, and if all your energies are spent tackling intrusion by hackers, you can miss more obvious causes of data breaches. The data manager must assess how well the organization implements the whole range of necessary precautions.
There are accidental breaches, such as the civil servant who left a laptop on the train that held data about top-level military secrets. Sadly, some breaches aren’t accidental. I was once part of a panel interviewing a prospective Sales Director for an organization where the candidate announced proudly that he would bring to his job the complete database of customers from his previous job. As we hurriedly guided him towards the door, he indignantly protested his innocence. He somehow thought it was a perk.
In a well-known trial of investigative reporters for a national newspaper a few years ago, it was revealed that they had a list of phone numbers of government employees who, for a small fee, could reveal over the phone anything they needed about private individuals from the databases they were able to access.
Data precautions mean far more than putting up firewalls and establishing intrusion detection. The organization must document data lineage before preceding to data protection. Before you can sensibly assist members of the organization in the correct handling of sensitive or private data, you’ve got to know how the data is stored, who needs to access what parts of it and why, and where it goes.
From what I’ve said, you’ll understand the importance of implementing role-related data access as well as monitoring access to spot unusual or suspicious activity.
Disaster recovery planning – checking data resilience
The higher the potential cost to an organization of ‘losing’ certain data, the more resilient to loss it must be, which of course then dictates our disaster recovery planning, implementation and checking.
I remember once having to check on the extent to which an organization had acted on the requirements of planning for disaster recovery. The Data Center manager looked at me defiantly and said, “Oh that’s all right – we take backups!“. He might have said, “Oh that’s fine, all the important stuff is in the Cloud“.
Plans for disaster recovery must be ‘war-gamed’. It is surprising how quickly staff will realize that the organization simply wouldn’t recover from an unexpected data disaster.
Rules and practices for data (data standards)
It is also important to document the rules and practices, often referred to as data standards, for maintaining and documenting each classification of data. It might seem a strange solitary task that goes unnoticed. At times it is, but it is like making fire extinguishers and exhaustively documenting how each one should be used to tackle sources of fire.
It seems pointless because so many are never used, but there is no joy like the possession of a fire extinguisher when you smell burning, and of a set of rules and practices for data when a breach is suspected, or bad data is detected. These rules will apply to the various classifications of data that the mapping and surveying exercise will have produced.
Operational work
For the operations team, including database administrators, most of their work involves routine maintenance, supporting database applications, taking backups, resolving performance problems, managing access control, checking hardware, and checking for attempts at intrusion.
This work is almost undetectable, until things go wrong. It is important that, as well as performing tasks, they report on the work and pass on any concerns that they have. To do this, they need access to documents that define the organization’s rules and practices for data.
You can’t say to your manager that something is wrong if you don’t know if it is against the rules. Operational staff constitute the eyes and ears of the senior IT Management and must be given all the necessary tools to do their tasks, such as monitoring servers and databases, discovering data and protecting production data.
Data documentation
While auditing an organization’s handling of data, it has been impossible not to notice that the quality of database and service documentation seem to be highly correlated to the organization’s overall standard of data governance. I’ve never established whether these are two unrelated symptoms of IT management skills or whether there is any causal link. However, an organization that insists on correct database documentation generally does data governance properly as well.
There are no industry standards for data documentation. No database developer comes to the work with a clear guidance for what should be documented, because the requirements vary so much between different types of organizations and the longevity of the applications. Documentation standards must be spelled out as part of data standards.
Data documentation and database documentation is best done diagrammatically, accompanied by terse but well-chosen phrases that encapsulate in plain language the types of data, its sensitivity, the entities and their relationships, the origin of the data, and all the downstream systems and applications that consume the data. The average IT manager doesn’t need to know all this when things are going well, but when they aren’t, up-to-date data documentation can save the day.
Data Quality
Data documentation provides the basis for effective data quality checks to ensure data consistency and information quality.
For a start, data documentation will tell us where in the metadata the facts about this data are kept. This in turn will tell use its provenance and lineage, and its source within the organization. We will now know the access and security regime which must be used for the data: is it sensitive, confidential, or private information? This will also allow us to check on data quality issues to make sure that the data conforms to its definition in the documentation, in terms of its value and range, to allow us to correct mistakes, omissions or duplication.
Summary
Until data governance became an essential part of running an organisation, there was usually a large disparity between what the management of any organisation, and its customers, believed happens in the day-to-day use of data, and the reality.
Data Governance ensures that organisations comply with the law, and ensures that vague sense of harmony, security and good practice with data matches the reality in the server room or the office.
Good practice in data governance has the side-effect of making it far easier to ensure that data is correct and kept in the right place. By shining a light on an area of IT that has never had the kudos of the startup, or the pioneer, the solution to problems with data suffered for years suddenly become blindingly obvious.
Tools in this post
You may also like
-

Article
Data cataloging: A giraffe’s eye view
In the latest DBAle podcast episode our hosts, Chris and Chris, tackled what they really mean by cataloging a database and how taking a ‘giraffe’s eye view’ approach to compliance is not enough. That’s because the most common data concerns for managers and execs center around where your sensitive data is, the risk it poses
-

Article
Meeting your CCPA needs with Data Classification and Masking
This article will explain how to import the data classification metadata for a SQL Server database into Data Masker, providing a masking plan that you can use to ensure the protection of all this data. By applying the data masking operation as part of an automated database provisioning process, you make it fast, repeatable and auditable.
-

Live training session
Cataloging and Masking AdventureWorks
AdventureWorks is a database we all know and love so there’s no place better to tackle one of the most challenging aspects of protecting data in non-Production environments. Join Chris Unwin in this session as they walk you step-by-step through getting AdventureWorks classified and masked for non-Production use in just 30 minutes. With the help
-
Live training session
Loading Existing Classifications into SQL Data Catalog
Classification is nothing new to companies – many have tried (and in some cases failed) to get columns tagged across their data estate. Much of this work is still usable, however. Join Chris Unwin, a Redgate Solution Engineer, as they take you through some of the best ways to persist your existing classifications into SQL
-
Webinar
POPIA - round up
-

Webinar
Sichere und schnelle Datenbankkopien bereitstellen
In diesem Webinar stellen wir Ihnen Redgates Strategie zur Bereitstellung sicherer Datenbankkopien vor – mit Fokus auf Datenschutz durch realitätsnahe Datenverschleierung. Erfahren Sie, wie Sie Daten effizient katalogisieren, maskieren und klonen, um Sicherheitsstandards einzuhalten und gleichzeitig die Benutzerfreundlichkeit zu wahren.