





Flyway Branching Walkthrough
I'll be using a SQL Server database call "Pubs" and some PowerShell scripting to demonstrate how we might configure a Flyway database project in source control to support branch-base database development. These scripts, together with the demonstration Flyway migration scripts, are available on GitHub.
We'll use a system that gives the same Flyway experience whichever Source Control system you use. I will use the terms 'Branch' and 'Merge' in their workflow sense, not in a Git-specific sense. I'll go into the nuts and bolts of integrating with a source control system in separate articles.
Releasing the latest development changes
We will start simply by looking at a special case, the release. I use this term 'release' to mean the creation of the migration script, or run of scripts, that is used in deployment to update a production database.
The production ('main') and development ('develop') branches within development are slightly different from other branches because they are both permanent. You almost never merge the development branch and then remove it, to create another one for the next release. It is a permanent branch because it holds the team's record of changes and their documentation.
To create a production release, you merely create a migration file that summarizes all the development branch changes, since the last release. We start by creating a first-cut migration, which is then refined and tested to ensure that no intended change is lost, that production data is retained intact and that no unintended bug or performance issue is introduced.
We'll demonstrate all this with the long-suffering Pubs database. The Pubs project folder is included with the framework, on GitHub.

There is also one 'Resources' folder that will be there for all the projects you add for this framework. It is best, where possible, to gather all the script-based tasks that we may need for this and any other related project in one place.
The main branch
The Pubs folder has the production, or main, branch. I don't call it main, to allow for cases where you are managing several databases (Pubs, Customers, Sales and so on) in Flyway, within the same framework. Each folder represents the main branch for that project, and each project uses the same shared set of resources.
Necessary files for every branch
The main branch, and every other branch, needs these three files:

- Preliminary.ps1 - Does all the necessary checks such as the existence of files and directories, and then creates a hashtable called DBDetails that provides all PowerShell scripts, even callbacks, with all the data they could possibly require. All the utility script blocks I use take DBDetails as a parameter. As it could get tedious to maintain this, I've added a utility to do this called Distribute-LatestVersionOfFile.ps1 (in Resources) to ensure this is always the latest version. This, and all the other code in the Resources directory, is executed every time you execute the preliminary.ps1 script, so you will always have the latest copies of the utilities.
- flyway.conf - Must be filled in when a branch is created and before it is used. The server and database are the most important items to fill in. The 'user' and 'installedBy' parameters need to be set in the flyway.conf in the user area. Each branch in the project must have a different database, of course.
- DirectoryNames.json - Define the names and paths to the project directories for migrations scripts, reports and so on
Branch directories
Each branch contains several sub-folders. If you don't like their names, you can define your own in the DirectoryNames.json file, but the idea is that each branch should be standard.
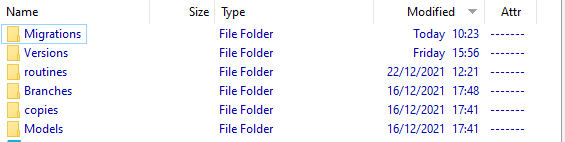
Not all the branch folders are used, for now, but I like to make all branches identical, so I put them all in.
- Migrations contains all our Flyway migration files (more below)
- Versions – contains object-level source, build scripts and reports for each version
- Branches – contains branches, such as develop, in this case.
- Copies – not used in this example but will hold a set of flyway.conf files used for automatically provisioning database copies on every migration, for CI processes
- Models – not used in this example but intended for JSON-based models of the database).
- Scripts – holds merge migration scripts. Ideally each merge uses a single migration script that 'rolls up' all required changes from a child branch
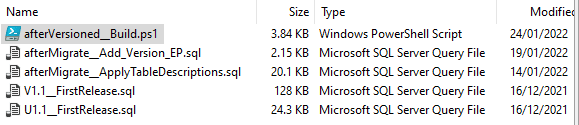
The Migrations directory contains all the migrations files that have been or will be released to the production database. In this case, it contains just one release, V1.1, which builds the 'classic' Pubs database, filled with the original data. By custom, a 'rolled-up' migration like this, created by joining 1.1.1. and 1.1.2, has the original branch and version-range in the file name (e.g., V1.1_FirstRelease_1-1-1to1-1-2.sql). However, I somehow wanted to leave development-only detail out of a production script.
There also one 'undo' (U1.1) migration file which reverses it. All the extra post-migration tasks that are run to facilitate team processes are called from the afterVersioned callback script.
Merging from develop to main
The development branch is in a subdirectory at Branches/develop. In general, every branch can have several sub-branches. We create each branch with the same directory structure and the same three files, DirectoryNames.json, flyway.conf, and preliminary.ps1 described previously. In another article, I'll introduce code that creates a branch automatically.
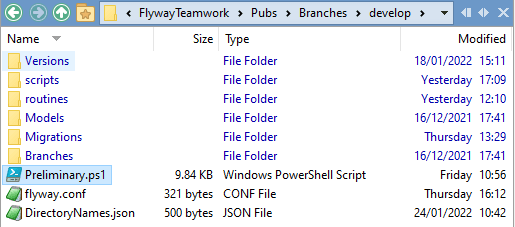
In this example, we have a development branch that has been worked on for some time. We want to release all the work that is now finished, and therefore is now in the Migrations sub-folder of the Develop branch, by merging it into the production (main) branch.
The merge will be more complicated if the main branch has changed in the meantime. Outside development, Production will, hopefully, only change via versioned patches, so these will appear as one or more active 'patch' branches off of the main branch. These would need to be deployed before the next planned release being prepared in the Develop branch. Depending on their importance, these patches can be pulled immediately into development, or they can be left until the release candidate is merged with production. They will only cause problems if they impinge on objects changed by the developers and which are in the development branch, and therefore part of the release.
To simplify things here, we'll assume that no patch or change has been made to production since V1.1, we can easily do a V1.2 release by updating the production branch, with the latest changes in development.
Merge strategies
The requirement is to produce a single, merge migration script, assigned a version number consistent with its position in the migration sequence at time of merge, which we can then test thoroughly.
With two close-coupled branches, main (production) and develop in this case, you have two possible strategies to help the merge: we can produce a first cut of this script either by concatenating the develop migration scripts or by using a Flyway "dry run" script.
Producing a first-cut merge migration script by concatenation
The easiest way of creating a first-cut merge migration file is to simply concatenate the individual migrations files in the correct order. To do this, I've created a short cmdlet that I've called Concatenate-Migrations, which you'll find in the Resources folder. It is, of course, possible to do it 'by hand' instead, but it is tedious and prone to inaccuracy if you get the order wrong.
Let's go ahead and do this. The first release (V1.1) included the V1.1.1 and V1.1.2 migrations, and the second release rolls up V1.1.3 to V1.1.11. We will hold the V1.1.12 release for the time being because it is just data which we must scrub for production anyway. We need it for the feature we'll be developing soon that allows us to search notes rapidly.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
<#
At the start we must change working directory to the branch we are working on (The develop branch)
#>
cd <ThePathTo>\FlywayTeamwork\Pubs\branches\develop
# we start off by finding out all we can about the branch and project
. '.\preliminary.ps1'
Write-Output @"
Processing the $($dbDetails.branch) branch of the $($dbDetails.project) project using $($dbDetails.database) database on $($dbDetails.server) server with user $($dbDetails.installedBy)"
"@
<#
We now save the concatenated script in the scripts subdirectory of the branch. The parameters are $TheDirectory, $Destination, StartVersion, Endversion
#>
Concatenate-Migrations "$pwd\$($dbDetails.migrationsPath)" `
"$pwd\$($dbDetails.ScriptsPath)\V1.12__SecondRelease1-1-3to1-1-11.sql" `
'1.1.3' '1.1.11'
We then copy this script into the pubs (main branch) directory, as follows:
copy-item -Path "$pwd\$($dbDetails.ScriptsPath)\V1.2__SecondRelease1-1-3to1-1-11.sql" `
"../../$($dbDetails.MigrationsPath)"
<#
Normally, this is just a first cut and we'd have to check it for the merge, but we know there haven't been any patches so this should 'just work'.
Now we can run the Flyway migration to update the development copy of the production branch database to the latest version:
#>
$TheBranch = $pwd #remember where you are
cd ../../ #migrate to the parent branch
. '.\preliminary.ps1'
$pword = "-password=$($dbDetails.pwd)"
Flyway $pword info
Flyway $pword migrate
cd $TheBranch
|
All done! We've done the migration. The production branch database in development is now updated to version 1.2.
|
1
|
Flyway $pword info
|

And pubs/main folder migrations now include the rolled-up migrations from development.
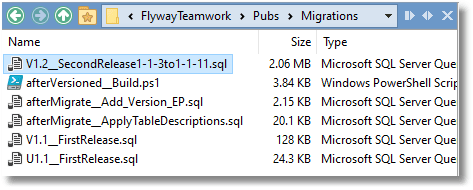
Producing a first-cut merge migration script using a Flyway "dry run"
You might think it is easier to create this merge migration file for the production branch by using the Flyway Teams DryRunOutput feature. In a way it is safer, and I'd suggest it if you've been controlling the actual SQL that is executed by means of placeholders.
Flyway creates the "dry run" script by executing the entire migration run, including the placeholder substitutions. In this example, one migration file is only executed if the server-version is high enough, and this decision is controlled by a placeholder. However, it defaults to executing first the lower version and then writes the higher version over the top, and I know that the server is at the right version. We would avoid all this by doing a Dry Run ….
|
1
|
Flyway $pword migrate '-target=1.1.11' "-dryRunOutput=$pwd\scripts\V1.2__SecondRelease1-1-3to1-1-11.sql"
|
…but there are two snags.
Firstly, you can only run a 'dry run' on a database that is at the start version, and in this branch, it will probably be at the end version. You would need to clone the database at the right version, or UNDO back to it, to dry-run all the necessary migrations steps.
Secondly, you'd need to edit the resulting dry-run file because it would create false entries in your Flyway Schema History table. You would need to nick out all the statements that write to this table. You would also need remove any SQL Statements added via callback files. Flyway also inserts statements that specify the database you should be using. Those must go. You've now got a script that looks uncannily like the original files concatenated. Were the dry-run output to include all the SQL that might be added by callback and migration scripts, either Java or script-based, I'd suggest that this was the best way, but it doesn't. Whichever way you do it, this merge migration is likely to involve a manual intervention.
Of course, this example looked easy, and it was. The script we produced was just a first-cut merge script. Normally, we'd need to take account of any interim patches and include a test cycle to prove that there are no conflicts or integration problems. However, because Production had had no interim patches, we could be confident that it would "just work".
Pre-merge testing
A first-cut script must be tested before the migration script is placed in the production branch's migration 'locations' for Flyway. Otherwise, you would end up with one or more corrective migrations to put things right. Conflicts or issues are unusual, especially if you spend time checking for them. I clone the database associated with the main/production branch and do 'what-if' testing with that until it checks out, and I can safely copy the migration file to the production branch. In a team, this involves everybody involved know that they need to review the code and test it on your cloned database before it is merged into the main branch. Any 'pull request' to the production branch should kick off a dedicated forum for a final check on the release-candidate. This process requires a neat summary of all the changes, and how any conflicts are resolved, especially where other specialist teams are involved, such as security and compliance. They aren't going to be please if you just try to wave the raw source-code at them enticingly.
If there is a way to sum up these preliminaries to adding the migration file to the production branch, it is that now is the time to correct any likely problems. Anything that slips through this process to derail a deployment should be considered a matter of shame and guilt to the development team.
Avoiding conflicting changes
The merge process is an intellectual task that varies according to the database and the way it was developed, and it is similar whatever the tools or methodologies. It can't be automated. However, it is helped by knowing the objects that have changed or deleted in the parent line of development since the branch was created. Additionally, you'll need to know the objects that your newly created or altered objects depend on. If the parent branch had had a migration that has altered any of your dependent objects, then they have to be checked. An experienced developer will ensure that the chances of merge conflicts are minimized in the planning and implementation by isolating the work as much as possible.
Assigning a version number to the merge migration script
You will notice that the production version 'numbers' we used are completely different from the development version numbers. You can, if you wish to preserve some sort of continuity, adopt a convention for version numbers to that, for example, the last two version numbers are reserved for the development branch and its child branches.
The important point though is that a version should only be assigned to the merge migration file at the point it is added to the parent's chain of migration files. The merge migration's location in the sequence must depend on the team decision that the branch's work is tested and ready to be merged into the parent's database. Trying to maintain ordered version numbers at any other time can end up being a cause of confusion and extra work. The parent branch has little or no interest in how a branch migration happened, as long as the merge migration works. Besides, the develop branch is permanent, so, there remains a record of every major sprint, feature or patch.
Reports, code checks and 'build artifacts'
Once the merge has been done, you'll notice that, using various script block tasks in my PowerShell framework, I've done several background tasks such as checking the code for the new version, seeing a list of what has changed, checking table issues and looking at table documentation. These are created and saved for every version (in the versions subfolder)
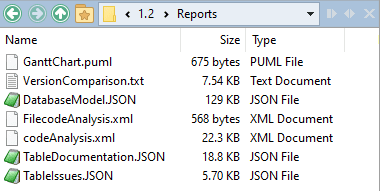
…I've also generated a build script for the new version, and an undo script:
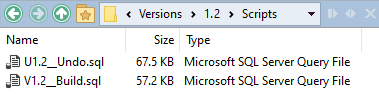
Finally, we have an object-level directory for version 1.2 that SQL Compare can subsequently use for database comparisons between any two versions (such as to detect drift):
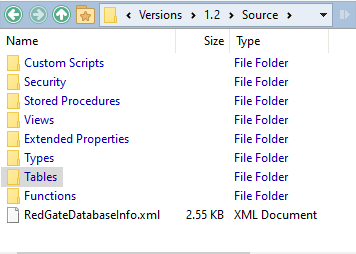
Along with each numbered version, in the Versions folder, there will always be a Current directory. At the end of every migration run, the Scripts sub-directory of Current is overwritten with the latest version, along with a version.json file that identifies the version, the person who did it, and the branch. This will be used to update source control to allow easy comparisons to be made.
Creating and merging a feature branch
Let's say that we now want to develop a new 'search' feature that allows rapid search of the notes in the 'people' schema, based on strings or lists of words.
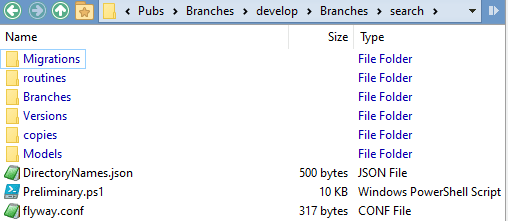
The first task is to create a new, temporary 'search' branch, off V1.1.12 of Develop. I don't mean creating a branch in your source control system, but in Flyway. We create the directory structure for the branch within the parent's \Branches directory, add our Preliminary.ps1 PowerShell script to do the routine checks, and a DirectoryNames JSON file that tells us how we want to name the various directories. We also fill out the Flyway.conf file, specifying a new clean database especially for this branch so we can develop the new search feature and test it out.
With all that done, we can walk the current working directory to the 'search' branch.
|
1
2
3
4
5
|
# At the start we must change working directory to the branch we are working
# on
cd <YourPathTo>\FlywayTeamwork\Pubs\branches\develop\Branches\search
# or if we are in the parent branch
cd .\Branches\search
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
#we start off by finding out all we can about the branch and project
. '.\preliminary.ps1'
<#
Now we have a hashtable with everything we need barring project-specific placeholders
we then set the placeholder values for the capability of the version of SQL Server.
#>
# we now set the password. This can be done as an environment variable. but that isn't quite as secure #/
$pword="-password=$($dbDetails.pwd)"
<#
we should now alert the user as to the branch the user is in
#>
Write-Output @"
Processing the $($dbDetails.branch) branch of the $($dbDetails.project) project using $($dbDetails.database) database on $($dbDetails.server) server with user $($dbDetails.installedBy)"
"@
|
We can see there is nothing in the Migrations directory yet, for our new search branch. We need to create a script that takes us up to the version in develop, at the point of branch, which is V1.1.12:
|
1
2
3
|
Concatenate-Migrations "$pwd\..\..\$($dbDetails.migrationsPath)" `
"$pwd\$($dbDetails.migrationsPath)\V1.1.12__toSearchBranch.sql" `
'1.1.1' '1.1.12'
|
This says, "go to the parent branch, join together all the migration files in the right order, and put them in the child branch Migrations directory."
And now we can migrate the currently empty database for the Search branch to V1.1.12:
|
1
2
3
|
Flyway $pword info
Flyway $pword clean
Flyway $pword migrate
|
Creating schema [classic] ... Creating schema [peeple] ... Creating Schema History table [PubsSearch].[dbo].[flyway_schema_history] ... Current version of schema [dbo]: null Migrating schema [dbo] to version "1.1.12 - toSearchBranch"
Now we have a good development environment. We have the database at the point of branch and the V1.1.12 migration added lots of extra data to allow us to test our new search feature.
We can recreate it if we make changes. We can either do a Clean followed by a migrate, or use clones generated from an image taken of the parent database at the point of branching. We can run all sorts of changes and build temporary test harnesses to check our work. Nobody outside the branch will care because we are isolated.
Let's say that we've now implemented our rapid search of the notes, using an inversion table, word search and string search:
|
1
2
3
|
Flyway $pword info
Flyway $pword clean
Flyway $pword migrate
|
Migrating schema [dbo] to version "1.1.12.1 - Search Functionality" Successfully applied 2 migrations to schema [dbo], now at version v1.1.12.1 (execution time 0 4:17.250s)
We have done everything in one file which we can now merge into development by giving it a version that it appropriate and at the next increment. Because there is only one migration file (V1.1.12.1__Search_Functionality.sql) other than the initial build file (V1.1.12__toSearchBranch.sql) we need only copy this file to the branch's parent. We rename it to correspond to the next migration for that branch, which is V1.1.13__Search_Functionality.sql.
As the sole developer in a feature branch, we are freed from most team constraints. If things go wrong, or if we want the elbow room to use various tools such as ER modelling, we can do some things that might cause frowns from developers working in the Pubs(main) or Development branch. This is because the only thing that needs not be ephemeral is the merge migration, and this is finalised at the point the branch ceases to exist. If you're like me, this is the point at which one can do more work. If things go horribly wrong, you can delete the database, create a new one with the same name on the same server, and start again. Flyway won't mind.
You can use SQL Clone to revert to an image at the starting version and baseline it. You can also use UNDOs with out any sense of guilt (they can cause havoc in any parent branch such as main or develop, in a team setting). An UNDO, automatically generated via SQL Compare, is provided.
Summary
I hope that this doesn't seem too complex as a way of doing a team-based development, but in my defence, this setup is meeting many of the requirements of an enterprise-scaled database. There is a measure of code analysis, object-level scripts for Source Control, the automatic generation of undo scripts, a script to do a Gantt chart of progress. For anything missing, I've illustrated DevOps ways of adding your favourite component. Although I've used SQL Server tools for all the support tasks, they are easily extended for the specific tools for the RDBMS that you're using.
Tools in this post
You may also like

Article
Integrating Redgate Monitor Alerts with New Relic
This article demonstrates how to use a script notification, in PowerShell, to automatically send database alerts raised by Redgate Monitor as incidents to New Relic. This simple integration makes it easy to feed the detailed diagnostics that only a specialized database monitoring system such as Redgate Monitor provides, and the DBA team relies on for a rapid response, into a single, organization-wide incident management system.

Article
Testing Databases: What's Required?
An overview of the challenges of database testing and test data management, reviewing the different types of database test that need to run during development work, what sort of test data they require, and how to manage all the required data sets, during development, in a way that allows rapid cycles of parallel testing.

Article
Moving to Team-Based Database Development with Flyway
Describing a route from a basic, 'managed' system of database development to use of branching and merging and CI, using Flyway. By taking these steps, you'll reduce development conflicts, lift testing restrictions, and the organization will have much more flexibility on the release of features and bugfixes.

Article
SQL Clone v2.4 - run scripts during image creation
SQL Clone 2.4 incorporates a new T-SQL script runner that the team can use to mask sensitive or personal data, or to modify security and other configuration settings, prior to creating a clone.
Article
Automatically Tracking and Deploying Static Data in Flyway Enterprise
Static data is often required for the basic functioning of a database and any dependent applications. Therefore, it's vital that we can track this static data to understand how, when, and why it changed, and that we include any static data changes in our database deployments. Flyway Enterprise will now do both tasks automatically.

Article
Controlling how SQL Prompt Formats your Code: The Knobs and Dials
Phil Factor explores and discusses the current state of the art in SQL Formatting, as done automatically by SQL Prompt.
Loading comments...