A strategy for implementing database source control
Much has been written on the strategic benefits of having a database under source control though many articles are clear on “why” but conspicuously vague on “how”. Dave Poole tries to fill in some of the gaps.
Much has been written on the benefits of having a database under source control though many articles are clear on “why” but conspicuously vague on “how”. Prior to our organization’s decision to embrace Linux and other open-source technologies, one of our development teams had notable success using Redgate SQL Source Control for a data mart project. By looking closely at the way in which that tool approached the problem, we could extrapolate those techniques and apply them to the cloud-based data mart platforms we use, namely Amazon RedShift and Microfocus (was HP) Vertica.
This article describes what was required of our database source control solution, the challenges we faced and how we approached them, and how using Redgate SQL Source Control as a template helped. While some of the details are specific to RedShift and Vertica, the general requirements of the project, and the principles that we embraced, as a team, are applicable to any database source control solution.
What’s required of a database source control solution?
What are the points of friction in your existing processes? Which ones are causing the most pain? In our case, it was not knowing precisely what state the database was in, within each environment, meaning that we could never be sure if a deployment or rollback across the different environments would work as intended, or if testing against the database was valid.
Identifying this problem allowed us to come up with a list of the most important requirements for the initial phase of database source control adoption. The solution should allow the team to:
- Generate creation scripts for all objects in the database, at any version
- Tear down a database in any pre-production environment
- Rebuild a database at any version, in any pre-production environment
- Deploy from version ‘x’ to version ‘x+1’ in any environment, including production
- Roll back from version ‘x’ to version ‘x-1’ in any environment, including production
- Secure any deployment and rollback mechanism, per environment, so that only authorized people can run it
More generally, we knew that any process we implemented had to be as simple and automated as possible. We also wanted it to make our database changes highly visible to anyone with access to the source control system, regardless of whether they were team members.
Over-ambition is a poison chalice
If your overall goal is to achieve continuous and automated delivery for databases, but you’re starting from the basics of “how”, then you will need to be realistic about scope. Take the time to understand what is required to make database source control an integral part of a disciplined and well-understood change-control process; it is going to require an investment in time, skills, and processes, and probably organizational and cultural change.
In our case, we decided to limit our initial scope to stages 1-3 (as listed previously). We’d treat incremental deployment, as would be enacted in a production environment, as a challenge to be addressed in a second phase.
Our first goal, in the first phase, was to get to the stage where we could guarantee the starting point for a deployment, so that we could tear-down an existing development database, and rebuild it from version control, at any version. Once our build scripts were robust and reliable, we could move on to using Jenkins to request rebuilds of pre-production environments. This would allow us to build a database at a known version and practice deployment/rollback from that known starting point.
We also decided to restrict our efforts to only the required database objects i.e. only those object in RedShift and Vertica that we were currently using, rather than those we might use in future. Our rationale was that if we spent time catering for every possible database object, rather than just the ones we use, then we would increase the cost and time to adopt database source control with no guarantee of additional benefit. Remember that until software has been delivered and is in use it has cost, but no benefit.
It’s all about team work
While source control offers some benefits to an individual database developer, it only really pays off when it is adopted by the whole team, and so success depends on close collaboration between developers of code and developers of databases. It is not something an individual, or even a team of DBAs, can achieve in isolation.
As a team, we pursued the goal of database source control in a way that allowed us to articulate clearly our concerns or fears, as well as expressing the perceived benefits. For each area of doubt, we worked through the issues until we were reassured that our methodology was sound. In short, we focused more on the people and processes to make it work, than on the tools and technology.
Each team member worked on a part of the problem, according to his or her strengths, and so we had a sense of shared ownership of the overall solution. For example, I knew how to use system tables across a variety of databases to automate scripting of database objects, so I took on the task of writing an automated scripting solution.
Another team member, familiar with Git source control and how to use tagging and labelling to mark and retrieve software at any version and patch level, took on the challenge of how that could be applied to database source control, and how best to approach branching, merging and other source control disciplines. A third member had experience with tools such as Jenkins, which we would use to help build a deployment pipeline.
Our lead Vertica DBA did a lot of work with Hashicorp Vagrant and installation scripts to allow each of us to build a local Vertica development environment. In development, Vertica is a Virtual Box instance, built by Vagrant, and our starting point was to be able to perform a rebuild by running a script from the command line.
A fifth team member, with experience of the command line tools for RedShift (psql) and Vertica (vsql) worked on the mechanism that we could use to determine if a deployment action had taken place, and therefore to proceed to the next step, or trigger appropriate rollback scripts.
Although our initial goals did not extend to production, there was no point developing a process that would not, ultimately, be fit for that purpose. Therefore, we also worked closely with the DBAs on our production systems to make sure that any process we devised would work in the heat of a critical 3:00am production issue, requiring rapid deployment.
Implementing Redshift/Vertica database source control
Even a difficult problem becomes easier when you know how to solve it. Our previous experience with Redgate SQL Source Control had shown us how to solve the problem. There were a number of ideas we particularly liked:
- Database objects are scripted out as a file per object
- Files take their names from the object they represent
- The folder structure closely mimics the structure of database objects as they appear in SQL Server Management studio (SSMS).
- Data is given its own directory. Data files will be given the same name as the table into which they load data.
We encountered certain differences between RedShift, Vertica and SQL Server in terms of object names, how object dependencies were implemented, as well as database scripting options. There presented us with some version control challenges but also some opportunities.
Source control architecture: folder structure
Redgate SQL Source Control includes table constraints and sp_addextendedproperty commands in the same file as the CREATE TABLE command. This makes sense for SQL Server, which enforces data referential integrity using primary keys, unique keys and foreign keys, and so dictates the other in which tables are built.
In RedShift and Vertica these items are simply metadata, which merely provide hints to the query optimiser. The constraints are not enforced, by default. You can decide to switch on constraint enforcement though this comes at a high cost in terms of CPU and memory utilization.
Although unenforced constraints are terrible from the point of data husbandry, it did allow us to categorize the dependencies between data objects as follows:
| Dependency category | Description |
|---|---|
| Natural | Schemas must exist before tables can be built
Tables must exist before views can be built Objects must exist before descriptions can be attached to them. |
| Artificial | Foreign keys dictate the order in which tables must be built. As constraints are not enforced in Vertica or RedShift there is no advantage in creating these until the last moment. |
To take advantage of the relaxed constraint regime in Vertica and Redshift, which allowed us to simply build the tables in any order, we decided to break from SSC folder structure, and instead created separate folders for each constraint type, and a folder explicitly for the data dictionary descriptions. This had the following advantages:
- Descriptions of objects can be maintained separately, without indicating that the
CREATETABLEscript needs to change. - If a deployment requires that a table constraint be dropped and then recreated at the end of the deployment, then we can simply call the appropriate DDL script for that constraint. This would not be possible if that table constraint were part of the table build script.
Source control architecture: file naming
If your source control solution must work across several platforms, as ours had to, then it’s wise to ensure something as fundamental as file naming doesn’t trip you up. We had the prototype source control system up and running on Ubuntu and Mac OS only for it to fail the first time we ran it on Windows. The reason? We exceeded the 260-character limit for fully qualified path and file names, on Windows workstations.
Database object names in SQL Server, Vertica and RedShift can be 128 characters long, so the file name for a schema-qualified table can be 261 characters:
- 2 x 128-character names
- 2 x 1 full stop
- 1 x 3 characters for the sql extension
This is before factoring in the folder structure. For that reason, we standardized on a simple code folder under the drive root in which to place our source controlled objects, and also on terse names for our database objects.
The 260-character limit can be overcome with a group policy change, or registry setting, but this would require rolling out across the entire estate.
Automated database scripting
In the absence of a tool like SQL Source Control, or even SQL Compare, for our RedShift or Vertica databases, we needed to devise an automated way to script an existing database into individual object scripts, in source control, as well as for developers to script out and commit DDL object scripts, during development work.
Dispelling fears of ‘false changes’ in Git
One of our concerns was that repeated scripting of a database would result in huge changes in our source control base. It would seem as if every object had changed. If true this would make it very difficult to know which objects had really changed. As discussed earlier, being able to express doubts, and devise experiments to confirm or remove them, is an important part of gaining adoption.
We used Git BASH, on our Windows workstations, to reassure ourselves that our scripting solution would not deluge Git with ‘false’ changes, on every commit. The experiment below illustrates this.
# Create a simple text file echo "This is a test" >test.txt # Does git see this file? git status
This produces a simple message as follows showing that git has seen the new file:
On branch master Your branch is ahead of 'origin/master' by 1 commit. (use "git push" to publish your local commits) Untracked files: (use "git add <file>..." to include in what will be committed) test.txt nothing added to commit but untracked files present (use "git add" to track)
So, we add the file to git, commit the change and ask how git sees the file
# add and commit the file git add . git commit -m "When applied this records our experimental test.txt file" # Does git see this file? git status
Now git knows the file is recorded in our local repository but has still to be pushed to our central repository.
On branch master Your branch is ahead of 'origin/master' by 1 commit. (use "git push" to publish your local commits) nothing to commit, working tree clean
Now let us delete the file and see what git does:
# Remove our experimental file rm test.txt # Does git see this file? git status
This shows us that git recognizes that the file has been removed an expects us to either update/commit or discard the changes:
On branch master
Your branch is ahead of 'origin/master' by 1 commit.
(use "git push" to publish your local commits)
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: test.txt
no changes added to commit (use "git add" and/or "git commit -a")
Now we regenerate the file, as we did at the start:
# Create a simple text file echo "This is a test" >test.txt # Does git see this file? git status
The message below shows that as far as git is concerned re-adding an identical file for an uncommitted delete will not be registered as additional activity under source control.
On branch master Your branch is ahead of 'origin/master' by 1 commit. (use "git push" to publish your local commits) noting to commit, working tree clean
Scripting out the database
Our automated scripting solution consisted of SQL DML queries to write SQL DDL commands. In Vertica, there is an explicit EXPORT_OBJECTS() function that will script all database objects to which the user has been granted permissions to a single file (overall_db_script.sql). For RedShift, there is no explicit scripting function but Amazon provide many handy queries on which we could base our DML queries. The RedShift queries produced a file containing all objects of a particular type. For example, the data to produce the DDL to generate all database schema objects would be in a single file.
In Vertica, for example, the result is a single SQL script that looks something like the following:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
CREATE SCHEMA STAGING; COMMENT ON SCHEMA STAGING IS 'The landing area for the data warehouse'; CREATE SCHEMA REF; COMMENT ON SCHEMA REF IS 'Primary source of reference data'; CREATE SEQUENCE STAGING.Seq_UserAgent CACHE 100; CREATE TABLE STAGING.UserAgent ( UserAgentId INT NOT NULL DEFAULT nextval('STAGING.Seq_UserAgent'), etc ); ALTER TABLE STAGING.UserAgent ADD CONSTRAINT PK_UserAgent PRIMARY KEY(UserAgentID) DISABLED; COMMENT ON TABLE STAGING.UserAgent IS 'Captures the web browser user agent'; …etc |
Splitting out the individual object scripts
The next task was to chop this single script into individual SQL files, each to the appropriate source-controlled directories, replacing any existing files. These individual files could then be committed to our Git repository.
We did this using the bash utilities grep, awk and csplit. The CREATE TABLE, CREATE VIEW and CREATE PROJECTION commands spread across multiple lines whereas everything else is a line per command.
For the single-line commands, we use grep to extract each of the various and then some awk programs to split and format them into separate .sql files and save them to the correct directory in source control. For CREATE SCHEMA commands in the previous listings, for example, we end up with a file per schema in a folder, called /schema/, each file containing the relevant CREATE SCHEMA command. For those interested in the details, I’ve included as a download a Vertica_ProcessOneLineCommands workfile, showing a typical example of both the grep command and a one_line_create.awk program we use to do the splitting.
We used a similar technique from processing the multi-line commands, such as CREATE TABLE, CREATE VIEW and CREATE PROJECTION, but using the Linux csplit command to separate out the different SQL commands into separate files, and we had to deal with the added complication that different flavors of Linux implement commands such as csplit slightly differently. The csplit command produced a file per individual object, but each file with a generic vertica_object_xxx filename. We then use an awk program to extract the CREATE TABLE, CREATE VIEW or CREATE PROJECTION command and the name of the object it is trying to create. Again, I’ve included typical example as a downloadable Vertica_ProcessMultiLineCommands workfile.
Even in a data mart with many tables and views, the number of objects produced by these processes is trivial.
Other benefits of automated database scripting
Automated scripting presents some additional benefits:
- It standardizes scripts, thus reducing heated, but pointless arguments on formatting
- It speeds up scripting
To clarify the latter point, I may write out a quick script to create a table in my local copy of the data mart database, with all its constraints, table and column descriptions. After executing that script, I can use the automated scripting method so that all the objects created are correctly separated out into the standardized format in their correct source-controlled folders:
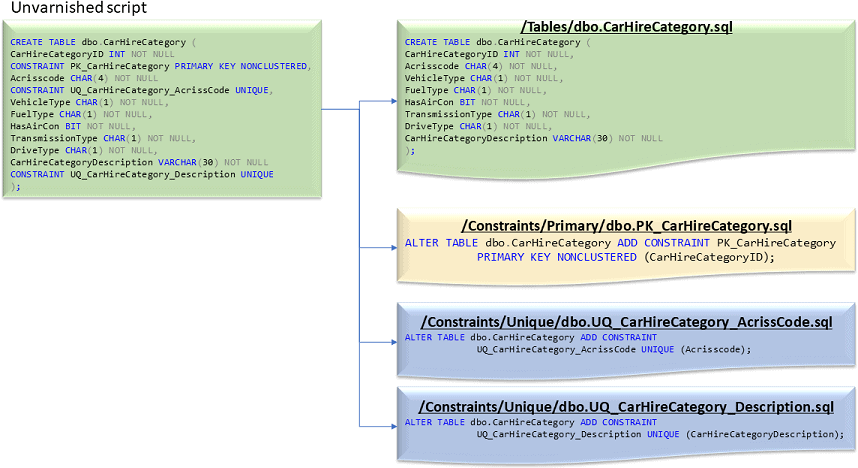
I do not need to be concerned with my unvarnished script matching agreed formatting standards or whether to choose to script constraints inline or at the end of a table create script. Automated scripting will take care of that for me.
Data under source control
Redgate SQL Source Control allows the ‘static’ data in a table to be placed under source control. This is an essential feature, given that we want to spin up a fully working database instance. It creates a SQL file that has the same name as the table create script, but resides in a “data” folder. These files contain an INSERT INTO query for every record.
The same approach can be taken with AWS RedShift and Vertica but as column stores they prefer to bulk insert data using their respective versions of the COPY command.
Perhaps a future version of Redgate SSC could give the option to export files in a format suitable for BULK INSERT or bcp. This would make it more practical to place data from larger tables under source control.
Tear down and rebuild of the personal development database
In the SQL Server world, Redgate provide several mechanisms for the provision of personal development copies of production databases.
- Redgate SQL Provision represents a comprehensive solution that not only caters for data but also for the masking of production data to alleviate compliance risks.
- Redgate SQL Compare snapshots allow a rapid build of the structure of a production database
- Redgate SQL Source Control somewhat more than a middle ground between the two as, in addition to allowing structure and smaller data sets to be deployed, we can deploy to a specific version.
In the absence of such tools for Vertica and RedShift we had to provide our own mechanism, which was either based on iterating through the individual SQL files or concatenating them into one big deployment script. Through experimentation, we found that concatenating the individual scripts and executing the resulting multi-object script performed better and was more reliable.
We used the Linux cat command to do this, for example:
cat tables/*.sql > all_objects.sql cat views/*.sql >> all_objects.sql cat data_dictionary/*.sql >> all_objects.sql …etc psql -f all_objects.sql
For Vertica it is somewhat simpler because we still have the overall_db_script.sql containing all objects we need to deploy, but there are however some pitfalls we had to consider.
Vertica has explicit commands to describe how data is distributed, when the database is on a multi-node cluster. As our development machines are single node VirtualBox instances, we needed the facility to strip out these clauses.
Vertica has something akin to the SQL Server index tuning wizard, except on Vertica it is recommended that this be used. It results in new system schema and objects within those schema that are picked up by the EXPORT_OBJECTS() function. Fortunately, EXPORT_OBJECTS will accept a comma-delimited list of schemas, and we can choose the relevant schemas by running the simple query shown below:
|
1 2 3 4 |
SELECT schema_name FROM v_catalog.schemata WHERE is_system_schema=false AND schema_name NOT LIKE ‘v_%’; |
So far, we have found two specific problem areas that exist in our production environment of which we were unaware:
- Just as in SQL Server 2000, Vertica dependency tracking is a bit hit and miss. We found this when the build scripts tried to create a table using a sequence that didn’t exist.
- Partition functions may be scripted in a way that implements the desired behavior but with its own interpretation of the SQL code. We had to write the partition functions for which this situation occurred.
Rebuild performance
We found that RedShift and Vertica perform very differently when deploying many objects. For around 15,000 objects on RedShift we saw a build time of around 2 hours. Vertica is consistently below 10 minutes. We found that both RedShift and Vertica are relatively quick to ingest data.
Incremental deployments and deltas
Once the process of tearing down and rebuilding a database is robust and reliable we can move onto the next phase and address the challenge of incremental deployments.
Precisely how we choose to implement an alteration to an existing database object depends on several factors: –
- Volume of data
- Frequency of access
- Method of access
- Service level agreements. Do we have to perform the change while the system is in use?
- Time to execute/rollback
- Rollback approach. Is a full return to pre-deployment conditions really possible?
- Database and application dependencies
In addition, a script per object means that a delta deployment could involve many scripts. This suggests that we need something akin to a manifest to specify which scripts need to be run, for either a deployment or rollback. The manifest concept is a useful one and its implementation suggests that we need two new folders in our source control folder structure
- A manifest folder to hold our deployment/rollback manifests
- A delta folder so that alterations to objects and removal of objects can be achieved
In SQL Server, we could use SQLCMD mode and use the :r command to point to the files we wish to run. This allowed the execution of a single master script which in turn would call all dependent scripts making up that deployment or rollback.
We had to build and equivalent mechanism using bash, psql and vsql.
A manifest file would look something similar to the example shown below:
# JIRA Ticket number 32768 # ==================== # Purpose: # ====== # To do stuff # Deployment scripts # ============== + tables/REF.PostCodeGeography.sql + tables/STAGING.PostCodeGeography.sql + data/PostCodeGeography.sql + constraint/PK/REF.PostCodeGeographyPK.sql + constraint/PK/STAGING.PostCodeGeographyPK.sql + delta/JIRA32768/ValidatePostCodeGeography.sql # Rollback scripts # ============ ~ /delta/JIRA32768/rollback/DropPostCodeGeography.sql # END OF FILE
Our mechanism simply looks for lines with the appropriate prefix symbol
- # = Ignore. These lines contain comments only
- + = Deployment scripts
- ~ = Rollback scripts. We use a tilde symbol because bash and Linux command line utilities can be confused as to how to treat a minus sign
The longevity of the contents of both manifest and delta scripts need be only until a deployment is deemed successful and will not be rolled back. At this point, all the changes to the database schema will be reflected in the main source control files and folders as a result of running our process to script the database.
Given that our development, integration, test and other pre-production databases can be at different levels, it is useful to store a log of the enacted manifests and their scripts in the database itself. This helps to decide which manifests have been deployed or are still to be deployed.
Summary: key principles when adopting database source control
Source control is an evolving topic, even in the development community. Although source control by code developers is considerably ahead of their database developer brethren, techniques and practices are still emerging while others are being discarded.
The 2018 State of Database DevOps reveals that only 52% of respondents use version control. As this percentage increases I expect this to drive further changes to source control techniques and practices as the needs of database developers gain in importance. Here’s some of the key points we have learned so far:
Maintain Discipline
If source control is used as part of a disciplined process, the fastest way to mess it up is to step outside of that disciplined process.
Suppose that you follow a deployment pipeline that consists of executing a manifest through development, integration, test, and so on, all the way to production. If you decide to deploy something outside of this pipeline then although you may fix an immediate localized problem, you have now broken the pipeline. You’ll now have to expend considerable effort in bringing everything back into sync. If your process has some rough edges then fix those rough edges, don’t try and circumvent the process.
Deploy small, deploy often
A few years ago, a deployment to production was a tense and formal process. Deployments were quite large and elaborate and the complexity of the scripts were considerable. A better practice is to have many smaller deployments rather than larger ones. A significant amount of complexity in the deployment scripts was to mitigate the combination of things that could go wrong with the deployment. Smaller deployments mean fewer combinations of things that could go wrong.
Frequent commits, short-lived branches
Ways of working that were de rigueur 18 months ago have fallen out of favour. An example of this would be the way in which source code branches are used. Although some points are still being contested there is emerging consensus on certain practices:
- New working code should be checked in frequently
- The longer a source control branch lives the more likely it is to cause problems when merged back into the trunk
- While in development, pull code from the branch representing production as often as possible.
Use 3rd party tools to replace complex processes
Unless you are in the business of building and selling database tools a reasonably priced 3rd party tool is an attractive alternative to building your own tool to cater for a process that is inherently complex.
Even though Vertica gives us a head start by providing an explicit EXPORT_OBJECTS() function, this advantage is reduced when we add the scripts to implement the deployment of deltas using a manifest system. Our solution has suddenly grown to the point where there are a lot of moving parts. We have a working prototype, but one with a lot of moving parts and some concerns over the skills required to maintain the solution.
RedShift requires considerably more queries, bash and awk scripts to produce scripts suitable for source control. The complexity is such that the team looking after the RedShift cluster have decided to evaluate alternative tools such as the recently open-sourced Goldman Sachs Obevo. As RedShift is based on Postgres 8 many Postgres tools are quite happy to work with RedShift.
Vertica has many strengths. Even though it was originally a fork from Postgres its compatibility with Postgres is low and it is a niche product. As such, third party tools are few and far between.
Further Reading
- https://www.red-gate.com/simple-talk/sql/sql-tools/simple-talk-source-control/
- https://www.red-gate.com/simple-talk/sql/database-delivery/database-version-control/
Tools in this post
You may also like
-

Article
Customer tips for improving productivity with Redgate products
We recently invited our customers to share their top tips for improving productivity in the first Redgate Tool Tips Swap. This post outlines their hints for using Redgate products to boost productivity and includes relevant training resources to further your learning. SQL Prompt Share formatting settings across your team to consistently format code before checking
-

Article
Overcoming Database DevOps Challenges: Part 1
As part of our research for the 2021 State of Database DevOps report, we asked 3,000+ recipients what they consider to be the greatest challenge when integrating database changes into a DevOps process. According to the respondents, these are the most important challenges facing database professionals when introducing DevOps practices to database development. Three of
-

Article
Merging a Conflict with SQL Source Control and Beyond Compare
Tony Davis explains how to resolve simple merge conflicts, such as conflicting changes to the same stored procedure, using SQL Source Control and a merge tool such as Beyond Compare.
-
Article
Source controlling database users
Where developers have their own databases, you need to ensure the user accounts are configured identically across all development and test server, or you'll inevitably hear the phrase “…but it works on my machine”. Alex Yates describes, strategically, how this might work.
-

Article
Using Filters to Fine-tune Redgate Database Deployments
Filters are used by Redgate's SQL Compare, SQL Source Control, DLM Dashboard, and SQL Change Automation. A typical use for a filter is to work on just one schema within a database or just a limited set of tables and routines. You would also want to use a filter to exclude certain object, such as database users, from comparisons. Phil Factor explains how they work, and how to create, edit and then use them within the various Redgate tools.