Practical PostgreSQL Schema Comparison with Redgate pgCompare
Managing PostgreSQL schema changes across environments can be challenging, especially with complex dependencies. pgCompare highlights differences between two databases and generates reliable deployment scripts. This article shows how to get started with the tool and how it simplifies everyday tasks like reviewing feature branch changes, auditing schema drift, and creating build scripts.
More professional developers are using PostgreSQL, but they often miss the tools that help to manage schema changes across database environments. Redgate’s pgCompare, now in public preview, is a cross-platform tool for comparing PostgreSQL database schemas. It visually highlights object-level differences between two live databases and will automatically generate a deployment script that, if applied to the target database, will make it identical to the source.
This article explains how pgCompare works, why it’s useful, and how it can help during development tasks such as merging feature branches, auditing changes, and generating build scripts. Along the way, I’ll also highlight a few PostgreSQL-specific ‘gotchas’ that you might encounter.
Trying out pgCompare
During the preview period, pgCompare is available to download with a registration form. When it’s officially released, it will be free for students, educators, small businesses, and non-commercial open-source projects. At this point, a paid Standard edition will also be available, offering additional functionality.
Why use pgCompare?
pgCompare is for any PostgreSQL user who needs to understand how and why two copies of a database are different, and then quickly generate a script to synchronize them. For example, when comparing a source development database (DEV) to a target test database (TEST), pgCompare can produce a SQL script to bring TEST up to date with the latest changes.
If you currently rely on pgAdmin’s Schema Diff for these sorts of tasks, you’ll find that pgCompare is faster and more reliable, especially for larger or more complex databases that often have complex object dependencies. It uses Redgate’s schema comparison technology to model dependencies correctly, handle differences in procedural code, functions, views, and security more precisely and manage complex objects without generating invalid scripts. The result is a deployment-ready script that ‘works first time’, even for large or heavily customized databases.
pgCompare is a great tool for developers who need to maintain consistent copies of a database across multiple environments and is especially useful for investigating schema drift and pinpointing exactly where the changes occurred. Beyond that, any user, developer or DBA, who needs confidence that their PostgreSQL schema deployment scripts are accurate, error-free, and repeatable will benefit from using it. It’s ideal for teams adopting PostgreSQL alongside SQL Server who are already familiar with a tool like Redgate’s SQL Compare, as they work very similarly.
Get started with pgCompare Community Edition
Like many of the new generation of Redgate tools such as Flyway, pgCompare is multi-platform and the current version will run on Windows, Linux, and macOS.
pgCompare (like Flyway) uses JDBC connection strings to connect to databases. When you open the tool, you’ll need to provide a username, password and connection string for both a source and target database. Having done so, pgCompare will run the comparison, inspecting the schemas of the two databases for differences. It will generate a list of database objects that exist only in the source (‘OnlyInSource’) or exist only in the target (‘OnlyInTarget’), that exist in both but are different (‘Different’) or exist in both and are identical (‘Equal’).
It presents side-by-side any differences in the SQL DDL code of each of the tables and code modules, so you can see, down to individual lines of SQL, what has changed and how:
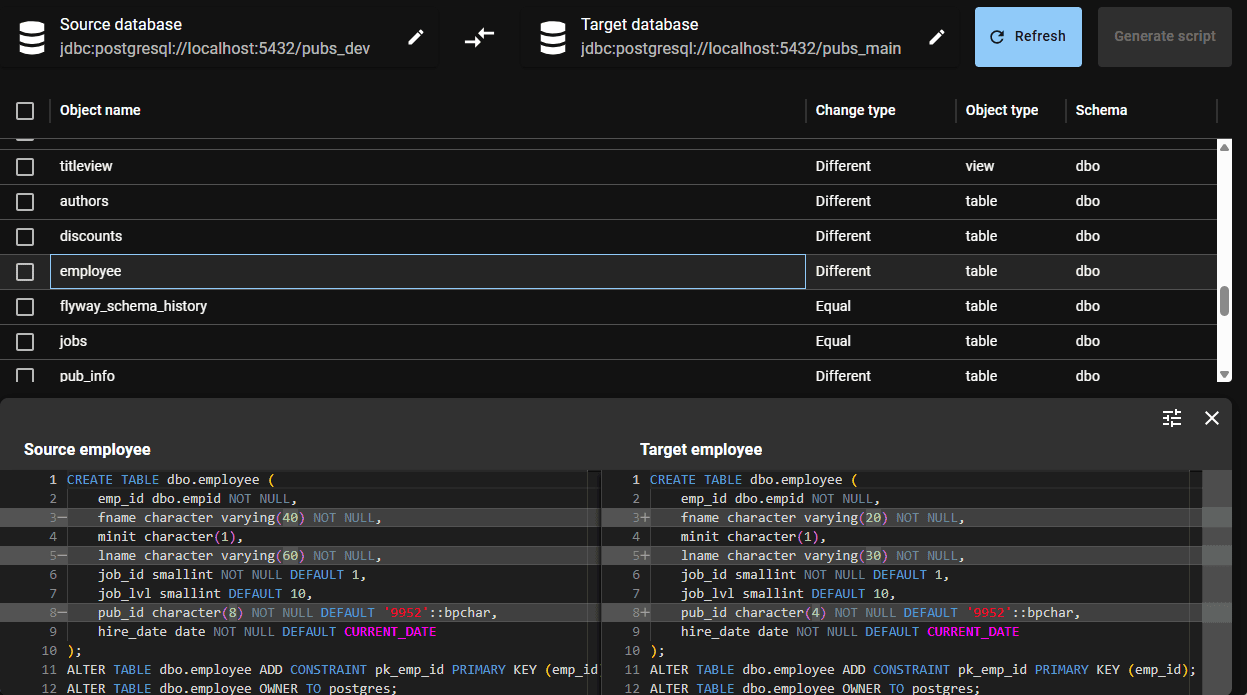
Having inspected the object-level differences, we can then either select all objects, or just those where the changes are ready to deploy and then hit “Generate script“.
pgCompare will generate a deployment script (a.k.a. a ‘synchronization script or ‘migration’ script) that will update the target database to make its schema the same as the source. The script will create any objects that exist only in the source, drop any objects that exist only in the target, and alter any objects that exist in both so their definitions match. It performs all operations in the correct dependency order. When altering tables, it preserves existing data wherever possible and issues a warning if it can’t, at which point you can inspect the script and make any necessary adjustments.
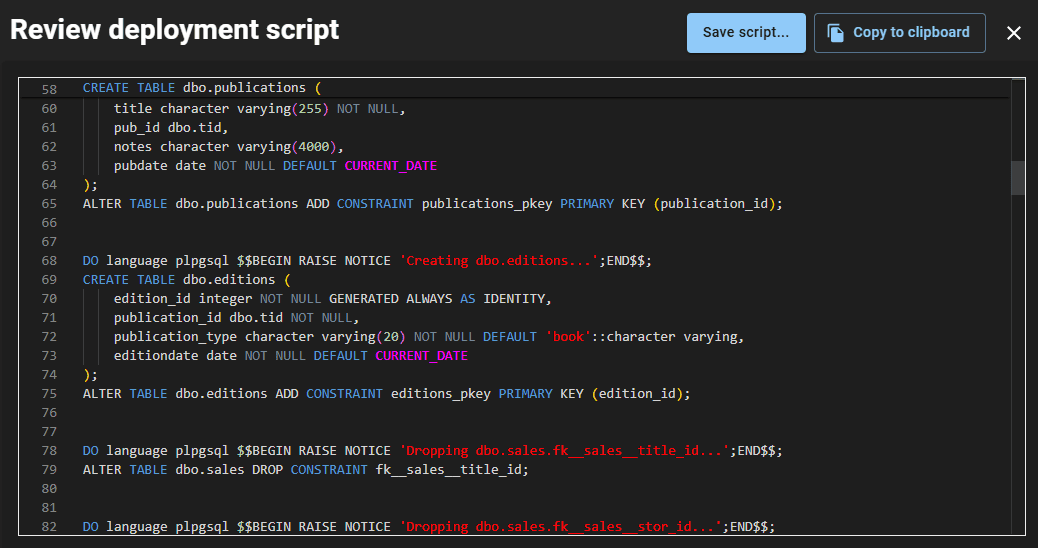
Uses for pgCompare in PostgreSQL development work
The most immediate development use I see for a tool like pgCompare is to inspect a feature branch, down to the object level, to make sure there are no potential conflicts or inconsistencies before merging it into the parent. You can’t do that sort of work in an automated pipeline.
However, it’s also useful for creating a build, or ‘baseline’ scripts for any given version of a database as well as for scripting out changes made via other visual design tools like Entity-Relationship Diagram tools.
Merging development work
pgCompare has an obvious and immediate use when merging a feature branch into the development trunk. Over the lifetime of a feature branch, other developers or teams may have made changes to the parent branch that could cause conflicts or inconsistencies at merge time. For example, someone might have modified the same table, column, or function definition in subtly different ways. These kinds of issues are hard to spot in source control alone, especially when teams are working across multiple branches or environments.
pgCompare provides a clear, visual comparison between the feature branch database and the parent branch, making potential conflicts immediately visible.
Scripting out a feature branch
When the work in a branch is complete, the developer raises a pull request, triggering a code review. At this point, the team will often want a script that shows all the schema changes made by the feature branch.
pgCompare makes this easy. If you create a local reference copy of the database at the start of the branch, then compare the completed branch (as source) to that reference (as target), it will generate a script that captures all the changes made during the branch. This gives reviewers a clear view of what’s changed, right down to individual objects and lines of SQL.
If needed, you can reverse the comparison to generate an undo script. This will roll back all the branch changes, allowing you to adjust the original migration scripts and reapply them cleanly, without upsetting Flyway.
Scripting out and auditing the changes made by a UI Design tool
If you’re using a visual design tool, such as an ERD editor, table builder, or any tool that makes changes directly to a live database, you can use pgCompare to audit and script those changes.
Before you start, create a copy of the database. Then make your design changes in the working database. When you’re done, compare the working version (source) to the original copy (target) to generate a synch script that is essentially a record of everything the design tool did. To generate an undo script that rolls back the changes, simply reverse the source and target.
Creating a build script or baseline script
One useful trick is to keep an empty database around to use as a comparison target. It makes it easy to generate a full build script for any given version of a database, so you can quickly spin up a fresh copy when needed.
In this example, I created an empty version of the Pubs for PostgreSQL database as the target and used the current development version of Pubs as the source. When we run the comparison, every object appears as OnlyInSource:
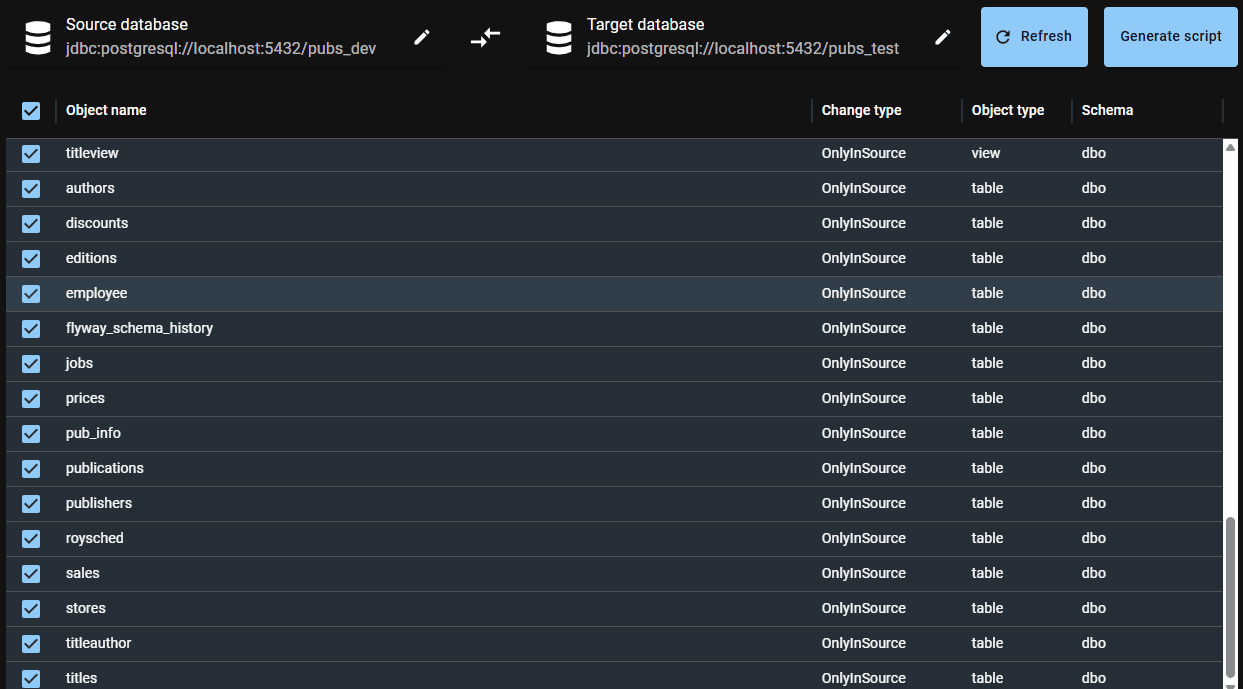
If we select all objects and hit “Generate Script“, pgCompare produces a script that builds out the entire schema from scratch, creating each object in the correct dependency order.
In this case, the source database is managed by Flyway, so the resulting script is essentially a baseline migration: it recreates the source schema at its current Flyway version. I can open the script in my preferred multi-RDBMS, JDBC-based editor (RazorSQL) and execute it on the empty target database.
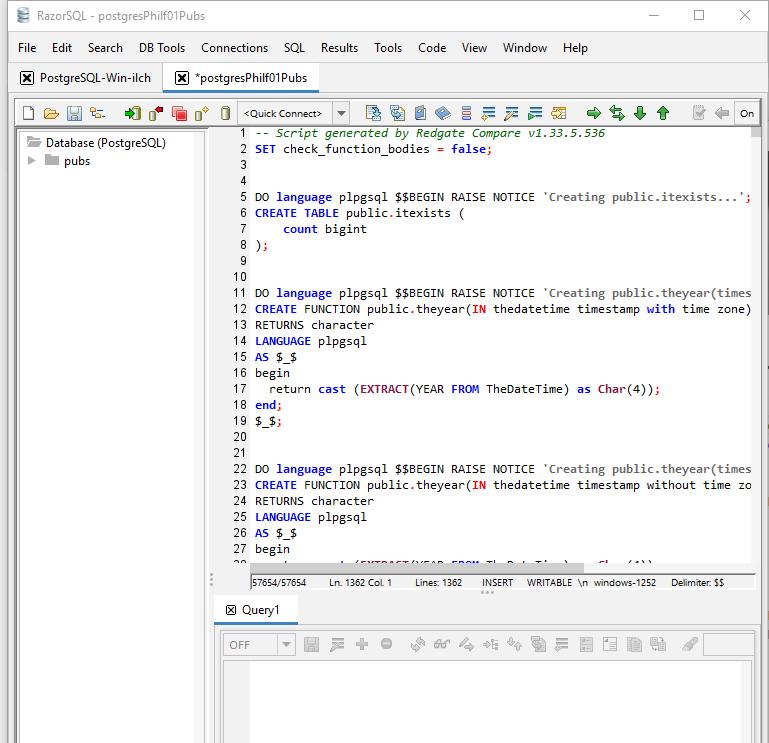
The result is a new copy of the flyway-managed database at the same schema version.
Back in pgCompare, if we re-run the schema comparison, we will see that the two databases are now identical.
This approach is also useful in version-controlled environments or CI pipelines. Once you’ve generated and verified the build script, you can check it into version control as a baseline for that schema version. It becomes the foundation for future migrations and ensures you can reliably recreate the database in test or integration environments without needing access to a live copy.
A detour into a few PostgreSQL gotchas
While testing out pgCompare, I hit several familiar PostgreSQL quirks that might trip up the uninitiated and so deserve a mention if you wish to try things out. These are not pgCompare issues, but PostgreSQL-specific behaviors that anyone working with schema comparison might encounter.
The pg_hba.conf trap
When attempting remote connections, you may see the doleful message from pgCompare:
FATAL: no pg_hba.conf entry for host "...", user "...", database "...", no encryption
PostgreSQL’s pg_hba.conf configuration file controls who can connect. A common issue is that your client (pgCompare in this case) resolves the server name to an IPv6 address (rather than IPv4), but your configuration doesn’t allow it.
Here is a safe configuration for development:
# Allow IPv4 local subnet host all all 192.168.68.0/24 md5 # Allow IPv6 loopback host all all ::1/128 md5 # Allow IPv6 link-local addresses host all all fe80::/10 md5
After making these changes, remember to reload the configuration with the more accommodating connection configuration:
|
1 |
SELECT pg_reload_conf(); |
The “wrong database” problem
PostgreSQL forces you to choose a database at connection time. Unlike SQL Server, it doesn’t support USE to switch databases mid-session.
A common mistake is to create a new database (CREATE DATABASE pubs), but then accidentally remain connected to the default (postgres) when running your build script. The result: all your schema objects go to the wrong place.
Instead, connect to the default postgres database, create your new database, then disconnect and reconnect to the newly created database. Now you can run your schema build and synchronization scripts. This distinction between the database catalog and the active database context often catches out SQL Server users moving to PostgreSQL.
What is and isn’t included in the Community edition?
With pgCompare, you get full object-level comparison, a side-by-side difference viewer, and migration script generation with dependency-aware deployment ordering.
Currently, pgCompare has no support for comparing to schema models or snapshots, and no comparison options to control how differences are detected or how the script is generated. That said, it’s more than enough to get started. Several enhancements are on the roadmap for the Standard Edition, including comparison options, support for Redgate Snapshots as source or target, and the ability to export comparison reports.
Summary
If you’re already familiar with Redgate’s SQL Compare, you’ll feel at home with pgCompare Community. It’s a straightforward, focused tool that allows you to compare PostgreSQL databases, explore object-level differences, and generate safe deployment scripts easily. Even for users new to Redgate tools, pgCompare’s clear interface and reliable output make it a useful addition to any PostgreSQL workflow and can supplement an automated workflow where a manual signoff is required that involves checking object-level differences.
For developers and DBAs who need to understand exactly what’s changed between PostgreSQL databases, and who want confidence in their deployment scripts, pgCompare provides an excellent foundation.
Tools in this post
You may also like
-

Article
How Redgate’s Foundry is Shaping the Future of Database Innovation with AI
Learn how Redgate’s Foundry drives AI innovation in database management - from intelligent monitoring and ML-based automation, to smarter SQL optimization.