It made me pause to think: I’d been scanning the forums of SQL Server Central when I came across a thread posted by “mahbub422”. His problem was how to model a binary tree. What he has written was a modified Adjacency List Model, using a flag to limit the size of the sub-tree.
Surely, I thought, there must be a better way of doing it?
The Adjacency List Tree
So as to illustrate the point he’d reached, I’ve cleaned up the code just a little bit (changed to ISO-11179 data element names, added constraints, shorten a 100-character name, removed an audit timestamp, remove an IDENTITY, made the flag CHAR(1) instead of INTEGER, etc) he posted this table. Oh, I changed the table name for this article. Hey, I just want to show the skeleton.
|
1 2 3 4 5 6 7 |
CREATE TABLE Binary_Tree (node_id INTEGER NOT NULL PRIMARY KEY, parent_node_id INTEGER NOT NULL, CHECK (parent_node_id <> node_id), node_flag CHAR(1) DEFAULT 'L' NOT NULL -- L= left child, R= right child CHECK (node_flag IN ('L', 'R')) user_first_name VARCHAR(25) NOT NULL); |
There are problems with this design of table such as the use of IDENTITY and flags. And root is neither left nor right, I guess it has to be a NULL.
The adjacency list is a way of “faking” pointer chains, the traditional programming method in procedural languages for handling trees. This is where we get terms like “parent”, “child”, “link” and so forth; these are classic assembly language terms.
There are major problems with the simple Adjacency List Model and this version is even more complicated.
You need to prevent orphans in any tree. That is, to be a tree there must be a path from every node back to the root node. This schema fails:
|
1 2 3 |
INSERT INTO Binary_Tree VALUES (1, 2, 'L', 'Sam'), (3, 4, 'R', 'Fred'); |
You need to prevent cycles. That is, nobody is his own boss. The simplest constraint for this is CHECK (parent_node_id <> node_id) and I am surprised that almost nobody bothers with it. But after that, it requires a trigger that follows the paths from the root. This schema fails as written.
|
1 2 3 4 5 |
INSERT INTO Binary_Tree VALUES (1, 2, 'L', 'Sam'), (1, 3, 'R', 'Fred'), (3, 4, 'L', 'John'), (4, 1, 'L', 'Loop'); |
The first thought is that you can constraint this model with a simple count of the children:
|
1 2 3 4 5 |
NOT EXISTS (SELECT node_id FROM Binary_Tree GROUP BY node_id HAVING COUNT(*) > 2) |
This is not enough. We also need to require that we have at most one left child and at most one right child. Here is one way:
|
1 2 3 4 5 6 7 |
NOT EXISTS (SELECT node_id FROM Binary_Tree GROUP BY node_id HAVING SUM(CASE WHEN node_flag = 'L' THEN 1 ELSE 0 END) > 1 OR SUM(CASE WHEN node_flag = 'R' THEN 1 ELSE 0 END) > 1) |
There are other constraints that make a graph a tree. We know that the number of edges in a tree is the number of nodes minus one so this is a connected graph. That constraint looks like this:
|
1 2 |
CHECK ((SELECT COUNT(*) FROM Binary_Tree) -1 -- edges = (SELECT COUNT(parent_node_id) FROM Binary_Tree)) - nodes |
I am showing this constraint and others as CHECK() clauses, but you will have to use TRIGGERs in SQL Server; I am being lazy about keeping the code as short as I can.
The Nested Set Solution
At this point, my regular readers are expecting me to pull out the Nested Set Model since I have written so much on it over the years. If you don’t know how it works, you can Google it or get a copy of my TREES & HIERARCHIES book (ISBN: 978-1-55860-920-4)
|
1 2 3 4 5 |
CREATE TABLE NestTree (node_name CHAR(2) NOT NULL PRIMARY KEY, lft INTEGER NOT NULL UNIQUE CHECK (lft > 0), rgt INTEGER NOT NULL UNIQUE CHECK (rgt > 1), CONSTRAINT order_okay CHECK (lft < rgt)); |
NestTree
node_name lft rgt
===================
‘A’ 1 9
‘B’ 2 3
‘C’ 4 11
‘D’ 5 6
‘E’ 7 8
A nice thing is that the name of each node appears once and only once in the table. It avoids cycles easily and orphans are not possible. Now here are the kickers! How do you write a constraint to assure that this is a binary tree? Here is one way:
|
1 2 3 4 5 6 7 8 9 10 11 |
CHECK (2 <= ALL (SELECT COUNT (C.node_name) FROM NestTree AS C LEFT OUTER JOIN NestTree AS P ON P.lft = (SELECT MAX(lft) FROM NestTree AS S WHERE C.lft > S.lft AND C.lft < S.rgt))) |
Yes, that is ugly code. And most SQL programmers do not know about the ALL() predicates. See if you can write a simpler constraint.
The Binary Heap
Binary trees have lots of known mathematical properties. For example, the number of distinct binary trees with (n) nodes is called a Catalan number and it is give by the formula ((2n)!/((n+1)!n!)). The literature is full of various kinds of binary trees:
- Perfect binary tree:
- a binary tree in which each node has exactly zero or two children and all leaf nodes are at the same level. A perfect binary tree has exactly
((2^h)-1)nodes, where (h) is the height. Every perfect binary tree is a full binary tree and a complete binary tree. - Balanced binary tree:
- a binary tree where no leaf is more than a certain amount farther from the root than any other leaf. See also AVL tree, red-black tree, height-balanced tree, weight-balanced tree, and B-tree.
- AVL tree:
- A balanced binary tree where the heights of the two subtrees rooted at a node differ from each other by at most one. The structure is named for the inventors, Adelson-Velskii and Landis (1962).
- Height-balanced tree:
- a tree whose subtrees differ in height by no more than one and the subtrees are height-balanced, too. An empty tree is height-balanced. A binary tree can be skewed to one side or the other. As an extreme example, imagine a binary tree with only left children, all in a straight line. The ideal situation is to have a balanced binary tree — one that is as shallow as possible because at each subtree the left and right children are the same size or no more than one node different. This will give us a worst search time of LOG2(n) tries for a set of(n) nodes.
- Fibonacci tree:
- A variant of a binary tree where a tree of order(n) where
(n > 1)has a left subtree of ordern-1and a right subtree of order(n-2). An order 0 Fibonacci tree has no nodes, and an order 1 tree has 1 node. A Fibonacci tree of order(n) has(F(n + 2) - 1)nodes, whereF(n)is the n-th Fibonacci number. A Fibonacci tree is the most unbalanced AVL tree possible.
The binary tree that we are interested in is called a heap. It is used for the HeapSort, which first appeared in J. W. J. Williams’ article published in the June 1964 issue of Communications of the ACM, titled “Algorithm number 232 – Heapsort. Currently, there is an article on using a version of a heap for data access in a virtual machine environment , ‘Think you’ve mastered the art of server performance? Think again’. by Poul-Henning Kamp
Start with a simple one dimensional array and put the root value in A[1], then the left child does into A[2] and the right child goes into A[3]. In general, the left child of the subtree root in location (n) of the array is A[2*n] and the right child is A[2*n +1].
Damjan S. Vujnovic (damjan@galeb.etf.bg.ac.yu) worked out the details of the following queries against a binary tree. Let’s construct a binary tree and load it with some sample data.
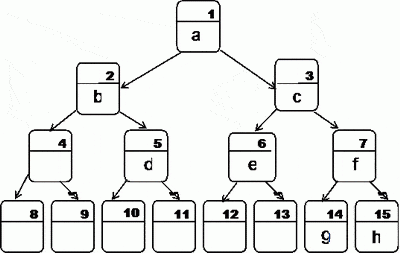
|
1 2 3 4 5 6 |
CREATE TABLE Binary_Tree (node_name CHAR(10) NOT NULL, location INTEGER NOT NULL PRIMARY KEY); INSERT INTO Binary_Tree(node_name, location) VALUES ('a', 1), ('B', 2), ('c', 3), ('d', 5), ('e', 6), ('f', 7), ('g', 14), ('h', 15); |
The following table is useful for doing queries on the Binary_Tree table.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE TABLE PowersOfTwo (exponent INTEGER NOT NULL PRIMARY KEY CHECK(exponent >= 0), pwr_two INTEGER NOT NULL UNIQUE CHECK(pwr_two >= 1) ); INSERT INTO PowersOfTwo VALUES (0, 1), (1, 2), (2, 4), (3, 8), (4, 16), (5, 32), (6, 64), (7, 128), (8, 256); |
You are going to fill the PowersOfTwo table just once or add it as a column to your Series auxiliary table. Skip the POWER() function and use a loop. If you need to use base two logarithms, the formula is (LOG2(n) = LOG(n)/LOG(2.0) â LOG(n)/0.69314718055994529.
Or you can build a look-up table that is rounded to integers. But wait! The PowersOfTwo table gives us that almost for free. LOG2(64) = 6 because (2^6) = 64; do that one in your head. Likewise, LOG(32) = 5 because (2^5) = 32. More on that later.
First, we know that the root of the whole tree is always at location one. That has to be the easiest query. Let’s try some other common queries.
Find the Parent of a Node
The immediate parent is easy to do from the definition:
|
1 2 3 4 5 6 |
SELECT @my_child, T1.node_name FROM Binary_Tree AS T1 WHERE B.location =(SELECT FLOOR(T2.location/2) AS parent_location FROM Binary_Tree AS T2 WHERE T2.node_name = @my_child); |
Yes, FLOOR() is redundant since we are doing integer math. I just wanted to show it for emphasis for generalizations. Let’s try another simple query.
Find the Immediate Children a Node
The immediate children also follow from the definition:
|
1 2 3 4 5 6 7 |
SELECT @my_parent_node_name, T1.node_name FROM Binary_Tree AS T1 --children WHERE T1.location IN (SELECT T2.location FROM Binary_Tree AS T2 -- parent WHERE T2.node_name = @my_parent_node_name AND T1.location IN ((2*T2.location), (2*T2.location + 1))); |
Again this is pretty simple.
Find the Number of Left (Right) Children in the Tree
This was actually the original poster’s query request.
|
1 2 3 4 |
SELECT SUM (CASE WHEN T1.location % 2.0 = 0 THEN 1 ELSE 0 END) AS left_count) FROM Binary_Tree AS T1 WHERE T1.location > 1; |
Again, this falls out from the definition of a heap. Notice that you have to decide what to do with the root, since it neither left or right.
Find Subtree Rooted at a Node
This is a more useful query, since you often use hierarchies for reporting. There are two ways to do this. You can use a Recursive CTE. This looks cool and modern! Wow! The recursive definition of a binary tree can be put directly into a recursive CTE. You know that given a node name for the subtree root node, you can use its location as the fixed point of the recursion, then use the “IN ((2*S1.location), (2*S1.location +1))” for the recursive step. It is a generalization of the immediate children query we just did.
This is a simple enough CTE so I am leaving it as an exercise. But recursion is always expensive. You need to compare it to the data driven version.
Finding a subtree rooted at a particular node is a little bit complicated. I am not giving you the math; I am putting it in a table instead. Note that the locations of the children of a node relative to location (n) as the root of a subtree are:
|
Level in Tree |
leftmost Location |
leftmost Location |
|
0 |
n |
n |
|
1 |
2*n |
2*n + 1 |
|
2 |
4*n |
4*n + 3 |
|
3 |
8*n |
8*n + 7 |
|
4 |
16*n |
16*n + 15 |
|
.. |
.. |
(..) |
|
k |
(2^k)*n |
((2^k)*n) +(2^k -1) |
If you are not sure about the depth of the tree, then pick a large (k), where (k=20) is probably good enough in the real world, you can use (k=100) and be safe.
You now have more math than you want; the important point is that there is a formula for all possible locations that subordinates of any given location. This is easier to see with examples.
Example one:
Is location 13 subordinate to location 3? It is obvious that the subordinates will locations grater than the subtree root location. So, is (3 <= 13)? Yep! Using the formula table I just gave and plugging in (n=3) we have
|
Level in Tree |
leftmost Location |
rightmost Location |
|
0 |
3 |
3 |
|
1 |
2*3 = 6 |
2*3 + 1 = 7 |
|
2 |
4*3 = 12 |
4*3 + 3 = 15 |
|
3 |
8*3 = 24 |
8*3 + 7 = 31 |
|
.. |
.. |
.. |
And sure enough at level 2, we find (13 BETWEEN 12 AND 15)! We have a winner!
Example two:
Is location 13 subordinate to location 2? Do the simple test; is (2 <= 13)? Yep! Using the formula table I just gave and plugging in (n=2) we have
|
Level in Tree |
leftmost Location |
rightmost Location |
|
0 |
2 |
2 |
|
1 |
2*2 = 4 |
2*2 + 1 = 5 |
|
2 |
4*2 = 8 |
4*2 + 3 = 11 |
|
3 |
8*2 = 16 |
8*2 + 7 = 23 |
|
4 |
16*2 = 32 |
16*2 + 15 = 47 |
Nope! We used the BETWEEN predicate to find winner, but the loser fails the (n BETWEEN leftmost AND rightmost) test. You do not have to look at any level where (leftmost > n) or (rightmost < n); this is the definition of NOT BETWEEN.
To find all the Superiors of n, reverse the logic. A superior has be a lesser number than the subordinate, so do that quick test first. Superiors have to be at a higher level by definition, so find the level of the candidate subordinate and don’t waste time on his subordinates. He must have one and only one superior each level. The path has to lead aback to the root, so (n=1) in the look up table.
But why bother with this look-up table approach when integer division by two will give you the answer? Try writing it both ways
Let’s do some programming exercises with the binary tree model. Create procedures that will do the following tasks.
- Delete a subtree. That is pretty easy, but it gives you a warm-up.
- Delete a node. If it is a leaf node (i.e. no children), it is also easy. However, if the target is not a leaf node, follow these rules
- If the parent node has two children, then promote the left child to parent node’s position.
- If the parent node has only a left child, then promote the left child to parent node’s position.
- If the parent node has only a right child, then promote the right child to parent node’s position.
- A binary tree is a search tree if for every node, it is true that all the left children are less than that parent node and all the right children are greater than the parent node. We will assume that all nodes have different values. The idea is that you can use it for searching for a given value by comparing each node to the search value, and then go left or right until you hit an equal value or fail.
- Balance your binary search tree. Now you have to work! A binary tree is balanced if for every node in the tree, the height of the left subtree is within one level of the height of the right subtree. The idea is that, if all search values are equally likely, this will give the best performance
The best three solutions will be given a prize of a printed First Edition copy of Defensive Database Programming By Alex Kuznetsov. We will take entries for a fortnight after the first Monday of publication, posted as comments to the article.
Joe’s decision and comments will be sent out in the newsletter, and published on the site. As always, Joe prefers an answer that…
- Solves the problem — Duh!
- Avoids proprietary features in SQL Server that will not port or be good across all releases, present and future.
- Uses Standard features in SQL Server that will be good across all releases, present and future. Extra points for porting code.
- Is clever but not obscure.
- Explains how you got your answer.
Load comments