There are many examples of how to build ASP.NET MVC (MVC) web applications on the web. However in order to get the basic ideas across, these examples often choose to pick rather simplistic database schemas. The problem is that the simple examples do not cover all the complicated issues that can show in the real world that has more complex databases.
I undertook this project because I wanted to check that some of my own libraries, which use Microsoft’s Entity Framework (EF), could handle a database that has a slightly more realistic level of complexity. For this I chose Microsoft’s sample AdventureWorksLT2012 database, which is a cut-down version of the larger AdventureWorks OLTP database. The AdventureWorks database is for a fictitious multinational manufacturing company producing and selling pedal cycles. See this link for a database diagram (pdf).
In the first article in this series I looked at the problems of getting Entity Framework (EF) to work with existing database like AdventureWorks. In this second article I look at how to build a web application that provided a user interface as would be used by an employee of AdventureWorks. I am using Microsoft’s ASP.NET MVC5 (MVC), various open-source libraries and the paid-for Kendo UI package providing various controls. In covering this I will describe a solution that aims to provide an interface with good performance when working with an existing database like AdventureWorks.
Before I start I should say that any of you with a SQL background might look at some of the issues raised and say ‘that could be done better in SQL’. However the point of this exercise is to work with the database as provided, i.e. no changes to the database are allowed. I wanted to find out if the various libraries I had assembled were up to working with an existing database ‘as is’, as sometime the project specification does not allow changes to the existing database.
The issues faced in building a web application
One of the fundamental issues that we face in building a complex web application is that what the business data held in the database is often not in the right format to display directly to the user. Let me give you a simple example from AdventureWorks.
I wanted to put up a list of existing companies that had bought from AdventureWorks before. This needed to quickly summarise who they were and give an idea of what level of purchasing they had done in the past. To do that I came up with following list as shown below:
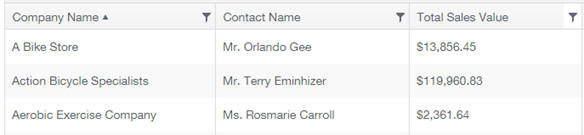
Now, to produce this I had to:
- Get the company name from the Customer table – easy
- Get the contact name. That needed me to combine the following properties from the Customer table:
- Title, which can be null
- FirstName
- MiddleName, which can be null
- LastName
- Suffix, which could be null
- For the Total Sales Value, I needed to sum the TotalDue property in the SalesOrderHeader table.
On top of that I want to:
- Have a pre-filter to only show customers who had bought before in this list.
- Be able to search by a company or contact name.
- Sort on any column.
- Be able to page the data, i.e. only show a selection of say 10 or 20 customers at a time and be able to step forwards/backwards through the list. This is because there are hundreds of customers.
This is a very typical requirement and it happens hundreds of times even a small business application. The architecture of the system need careful thought as to how to provide these capabilities with a) good performance and b) with the minimum of development effort. That is a challenge.
The power of LINQ with Entity Framework
Before I describe the approach I used I want to delve into the two technologies that will form the cornerstone of my solution, that is LINQ/IQueryable and Microsoft’s data access technology, Entity Framework (EF).
Note: for those of you who are familiar with LINQ and EF you can skip to the next section, ‘Separation of Concerns and Layered Architecture’.
a. LINQ/IQueryable
LINQ (LINQ stands for Language-Integrated Query) is a way of writing queries on data. The important point is that any query written in LINQ is held as a query and only executed when certain commands, like .ToList() are applied to that query. This allows software developers to write part of a filter/select command that can be added/extended later anywhere in the application that understands IQueryable.
Let me take a simple example using a subset of the Customer List problem I’ve just outlined. First let us select the customers who have bought from us before:
|
1 |
var realCustomers = Customers.Where (c => c.SalesOrderHeaders.Any()); |
Then I select the CompanyName and form the ContactName from this filtered list:
|
1 2 3 4 5 6 |
var details = realCustomers.Select( x => new { CompanyName = x.CompanyName, ContactName = x.Title + " " + x.FirstName + " " + x.MiddleName + " " + x.LastName + " " + x.Suffix }); |
This returns an IQueryable<> class, but it has not been executed, i.e. it is just a command and has not accessed the database yet. This means I can add the following filter commands onto the query:
|
1 |
var filteredQuery = details.Where (x => x.CompanyName.Contains("Bike")); |
Finally I might add something to add paging on to that query, e.g.
|
1 2 |
var finalQuery = filteredQuery.OrderBy(x => x.CompanyName) .Skip(pageSize*pageNumber).Take(pageSize); |
Hold that finalQuery as we step onto the next part of the solution which is…
b. Entity Framework
EF is a database access framework that works by converting LINQ queries into SQL Server database commands, i.e. T-SQL code, and it does it very well. So, if we set pageSize to 5 and the pageNumber to 0 and then execute the finalQuery mentioned previously by putting a .ToList() on the end we get the following results:
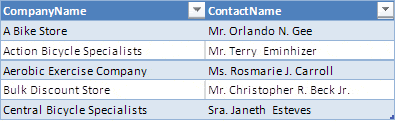
EF has converted the finalQuery into T-SQL and applied it to the database. If we look at the final SQL command then we will see that it has:
- Only selected the columns that it needs.
- The concatenation of the names has been turned into a T-SQL string addition, including replacing null items with an empty string.
- The two .
Where()'s, one looking for customers who have bought and the other looking for company names which contain “Bike”, are combined into a singleSQL WHEREclause. - The SQL command orders the data by CompanyName and then does a Skip + Take to return only the data that was requested.
For those who are interested here is the SQL command (text file) that EF produced from these concatenated queries.
Note: Some of the more eagled eyed of you will notice that the some of the names have extra spaces between them, e.g. there are two spaces between ‘Terry’ and ‘Emmihizer’ in the list above. That is because some of the name parts, like the MiddleName, can be null. This can be fixed in LINQ (and even easier in T-SQL) but I didn’t want to clutter this example with that extra code. In the real application I do handle that.
Separation of Concerns and Layered Architecture
There is a software approach, almost a rule, called Separation of Concerns. In a Microsoft document it defines this term as follows:
Separation of Concerns: Divide your application into distinct features with as little overlap in functionality as possible. The important factor is minimization of interaction points to achieve high cohesion and low coupling…
(Microsoft, Software Architecture and Design 2009, Key Principles of Software Architecture)
Applying Separation of Concerns with what we have learnt about LINQ and EF I have separated the applications into Layers (see Multilayered architecture). In .NET these are separate projects/assemblies but are bound together into one application, i.e. direct method calls between layers. (Note: In today’s cloud system, such as Azure, scaling up is done by having the whole application running multiple times rather than the previous approach of having each layer running on a separate server). My layers are:
- Data Layer:
Sometimes called the Infrastructure Layer, or Persistence Layer. This deals with the reading and writing data to the database. It should provideIQueryableversions of each table/class for reading. Depending on the software design used it will either allow direct write/update of a database class, or if using Domain-Driven Design may impose some factories/methods that need to be called to accomplish this. - Business Layer:
This will contain all the business logic that goes beyond simple read/write of data. For instance in the AdventureWorks system a new order starts in the ‘Pending’ state and needs to be ‘Approved’ before it can be taken forward. That sort of logic should live in this Layer and it will directly interact with theData Layer.I will not be covering the Business Layer in this article as I want to focus on the data access issues. - Service Layer:
Sometimes called the Application layer. This section’s job is to format the data flowing from theData Layerand theBusiness Layerto/from the format that thePresentation Layerneeds. It may need specialised handling for changing the data in theData sectionif a Domain-Driven Design approach is used. - Presentation Layer:
Sometimes called the UI (User Interface) Layer. This section’s job is to present the formatted data from theService Layerto either a user via a web page, to another system via say a RESTful interface. This section will also handle any paging, filtering, sorting etc. as required.
As you can see I have apportioned different parts of the query handling to different layers, i.e. queries/updates can be passed up the system and modified as it moves through the layers.
The Service Layer is key
My experience is that the Service Layer is one of the most useful layers because it totally separates the data model, i.e. the key data classes/tables that we have in the system, from the presentation layer.
Why is the service layer so useful? Because in any reasonably complex application the data model should be defined by the business process/data and not by how the user wants to see the data. By adding a service layer to shape/transform the data we keep the data model focused solely on the business needs and do not allow it to be contaminated by features that are only used for display.
Obviously we need another class more attuned to the Presentation Layer’s needs. These are often called Data Transfer Objects (DTOs). In my system the Service Layer methods do two things:
-
They take on the work of reformatting the data in the
Data LayerorBusiness Layerto/from a DTO, which holds the data in format that is suitable for thePresentation Layer. -
They call the correct commands in the
Data LayerorBusiness Layerto execute certain commands. The most obvious are the Create, Update or Delete commands to theData Layerto update data held in the database.
The only problem is – the Service Layer has a lot of really repetitive code, and boring to write! Personally I have set about fixing that with a library called GenericServices which I use in this example. However I want to concentrate on the fundament design issue, which is about using IQueryable/LINQ across the different architectural layers. I will mention GenericServices but only as one way to implement such a solution.
A real example: Producing a list of customers
We have had the theory so now we will look at how this works in practice. In the test application I designed a number of screens that the AdventureWork’s staff could use to find customers and manage their orders. Below you will see the main screen for listing and managing customer details.
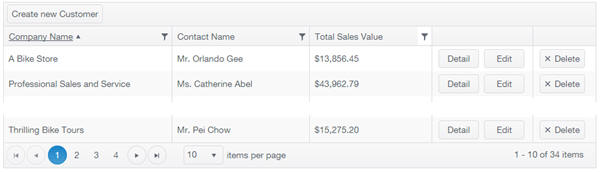
You saw an example earlier with some individual code to do something similar. The display above is similar but has a few more options for the user, such as paging, sorting, filtering plus create, update and delete features. Here I will explain what each layer in my application did to produce this end result.
a. The Data Layer
Clearly the main job of the Data Layer is to provide the data and handle any create, update or delete functions. This I did with EF commands orchestrated by the Service Layer (see next section).
In addition I needed to come up with some new, calculated values to use to help display the customer list. In early projects I simply hand-coded these using LINQ expressions. However I now wanted to have a general answer to its issue.
Just to recap, from the earlier example the Customer list needs three calculated properties:
HasBoughtBefore, which should be true if the customer has any sales ordersFullName, which combines the parts of the name to make something sensible for the user.TotalAllOrders, which sums all the order values to give total.
Now it may not be obvious but I need to create the commands to produce these calculated properties in a form that can be turned into a LINQ expression. I need to do it this way so that EF can turn that LINQ expression into an efficient SQL command. Therefore the simple solution of adding a calculated property to the EF data class as shown below then using it in a LINQ expression would throw an exception, as EF cannot handle properties that have calculations in them.
|
1 |
public bool HasBoughtBefore { get { return SalesOrderHeaders.Any(); } } |
After a lot of digging, and with the help of Jimmy Bogard’s AutoMapper blog, I found an elegant solution called DelegateDecompiler. What DelegateDecompiler does is allows you to mark calculated properties with a [Computed] attribute and in your LINQ query you add a call to .Decompile(). This then turns the calculated properties into a LINQ expression, which means EF can then execute that code.
So in my data layer I can add the following partial class to the Customer data class to add two of the three properties I need.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
public partial class Customer : IModifiedEntity { [Computed] public string FullName { get { return Title + (Title == null ? "" : " ") + FirstName + " " + LastName + " " + Suffix; } } /// <summary> /// This is true if a 'Customer' has bought anything before /// </summary> [Computed] public bool HasBoughtBefore { get { return SalesOrderHeaders.Any(); } } } |
The effect of using this approach is similar to using a computed column in a SQL database, but the calculation can use data from relationships as well as the class/table itself.
I should point out that DelegateDecompiler is very elegant, but complicated library so some types of LINQ commands are not supported. In particular calculation like TotalAllOrders does not work, nor does it support properties that need to access a local variable. I therefore fix this in the Service Layer, which I describe next.
Note: Even as this article is being published Dave Glick and Alexander Zaytsev are working on getting nullable properties/methods to work in DelegateDecompiler. My contribution is a Test Suite that checks DelegateDecompiler features with Entity Framework and produces documentation on what commands/features are supported. Please check back with the DelegateDecompiler project in the future to see what it supports.
b. The Service Layer
As I said earlier I find the Service Layer really helpful. The Service Layer looks after shaping/transforming the data and executing Data Layer or Business Layer commands. Of these the shaping/transforming of the data is the biggest, as there are so many different cases, sometime one or more per user screen.
I use DTOs, which are classes that hold only the data that is needed by the Presentation Layer, for shaping/transforming data. The service layer has to do Data-to-DTO and DTO-to-data conversions. In my early projects I hand-coded the data to DTO and DTO to data code. This worked but was incredibly repetitive, boring and needed Unit Tests to check I hand not fallen asleep during the process. I was committed to automating this process, which I have achieved using the AutoMapper library inside my GenericServices library.
AutoMapper is an excellent, conversion based mapper that can handle complex mappings between two classes, i.e. the data class and the DTO. I had come across AutoMapper years ago, but had rejected it because I did not support LINQ commands. However now it does support LINQ projections, which means it converts the copy into a LINQ expression which EF then uses to make an efficient SQL command.
Normally AutoMapper works out what to copy based on the names, e.g. CustomerID would copy to CustomerId in the DTO. It also does what is called ‘flattening’, e.g. if ‘Product’ has a relationship such that it can access a property by writing ProductCategory.Name then adding the same name without the full stop, i.e. ProductCategoryName, to the DTO will access that property.
AutoMapper also supports hard-coded conversion and this is how I solved the problem of the TotalAllOrders calculated property that I could not handle in the DataLayer. In AutoMapper we simply have to provide a customer LINQ expression for the property we want to override at the time we set up the mapping.
|
1 2 3 4 |
Mapper.CreateMap<Customer, ListCustomerDto>() .ForMember(d => d.TotalAllOrders, opt => opt.MapFrom(c => c.SalesOrderHeaders.Sum(x => (decimal?) x.TotalDue) ?? 0)); |
Where the ‘ListCustomerDto’ is a class that contain various properties that have the same name as properties in the ‘Customer’ class, plus a decimal property called TotalAllOrders that the special mapping will use. On conversion AutoMapper will apply the normal rules to all of the properties, but apply the LINQ expression to the TotalAllOrders property.
Note: The LINQ calculation for TotalAllOrders is complex because it is summing a property in a collection relationship. Because a collection can be empty LINQ correctly insists on the nullable version of Sum. This returns null for empty collections, which I replace with zero.
Finally I should say that my Service Layer used the GenericServices library to provide standard List, read Detail, Create, Update and Delete commands. This removes all the managing of the data accesses away from the Presentation Layer and provides standard methods that the MVC actions can call for each type of database command it needs.
c. The Presentation Layer
In this example the Presentation Layer produces HTML pages for the user to read. My software of choice here is ASP.NET MVC5, with the paid-for Telerik Kendo UI package for various UI controls, in this case a grid.
Because my Service Layer has taken a lot of the tedious shaping of the data away from the presentation layer that it can concentrate on its job – providing a first-class user experience. The presentation layer therefore has the job of showing the data and allowing the user to search, sort, group, filter, page etc. on that data.
My MVC Controllers code is very standard in nature, with the same code/methods used, but just the data types changes. This means that it is easy to auto-generate the Controller code using something called scaffolding. Here is a small snippet from the CustomerController showing how the customer list is generated.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
public class CustomersController : Controller { [DisplayName("Current Customers")] public ActionResult Index() { //the 'true' tells the Grid to only show rows where HasBoughtBefore is true return View(true); } public JsonResult IndexListRead([DataSourceRequest]DataSourceRequest request, IListService service) { var result = service.GetAll<ListCustomerDto>().ToDataSourceResult(request); return Json(result, JsonRequestBehavior.AllowGet); } //... the create, update, delete method left out for clarity } |
Note the IListService, which is the GenericServices List service, where we call GetAll<ListCustomerDto>(). to get the formatted DTO data. I then display this using a Kendo UI Pro Grid which takes an IQueryable query and adds its own filter, sort, group and paging controls to the query before executing the query.
MVC uses ‘Views’ to show a page and in the above case the MVC Kendo Grid was setup to use an Ajax call to get the data. In many cases MVC Views can be built by scaffolding, which is a built-in system that uses templates to create certain types of views. These templates do a reasonable job in most cases, but for more complex cases then some hand-coding is required.
d. Analysis of final SQL, and resulting changes
Finally I tackled performance by using Red Gates’ ANTS Performance Profiler to analyse the final SQL command (text file) that EF produced, and SQL Server’s query plans. The display is for existing customers, i.e. HasBoughtBefore is true, and filters the results to only include customers whose company name contained the string “bike”.
I am no SQL expert, but looking at the SQL command produced it seemed to me that sum of the SalesOrderHeader.TotalDue seemed to be done twice, once to see if it was null and then again if it wasn’t null. This didn’t seem too efficient so I changed the LINQ code to first check if there was any SalesOrderHeader before attempting the sum. The new LINQ code to define the TotalAllOrders property is shown below:
|
1 |
SalesOrderHeaders.Any() ? SalesOrderHeaders.Sum(x => x.TotalDue) : 0; |
This produced the following SQL command (text file), which a) seems simpler and b) was faster than the original SQL command.
In real life you should focus in on those areas of poor performance using a profiler that displays the SQL, so as to to hone the LINQ code. You then apply increasing levels of refactoring, right up to using direct SQL commands, to obtain the performance you need. However this does take development time so in some areas of a project a quickly written but possibly poor performing database access may be acceptable.
A Real Example: Handling composite keys
The last example was looking at the whole process from end to end. However we all know it is the little, detailed issues that can take the time. I had a few of them but to give you a flavour let me describe one around handling composite keys.
Quite a few of the tables in the AdventureWorks Lite database has composite keys, i.e. a primary key made up of two or more columns in the table. Now GenericServices is designed to handle composite keys and the Detail, Update and Delete services all take multiple keys. However there is one table in AdventureWorks Lite database where the keys can be a challenge: CustomerAddress. It is worth pointing out how to handle this in EF.
The picture below shows that the Customer has a collection of CustomerAddresses, which consists of a property called AddressType, which says if it’s their main office etc. and a link to a standard Address class. CustomerAddress has a composite key consisting of the CustomerID and the AddressID.
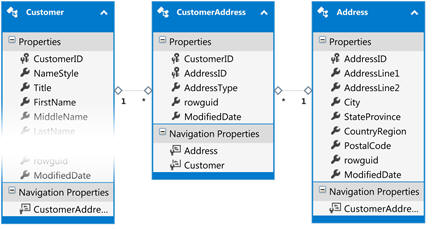
So, the problem comes when creating a new CustomerAddress. We need to create the CustomerAddress and the Address in the same commit so that they are consistent, but we also need to get the new AddressID to fill in part of the composite key on the CustomerAddress.
The answer was surprising easy because EF handles this as part of its relational fixup. To get this to work I create the CustomerAddress and set its EF Address relational property to a new Address type. We add the CustomerAddress entity to the database using db.CustomerAddresses.Add( myNewCustomerAddress) and call EF’s SaveChanges() and its done.
Any down sides to a LINQ/IQueryable design?
It is always good to think of what could be done better – that is how I got to write GenericServices. Looking at the approach outline above I would make the following comments:
- The proposed architecture is very reliant on LINQ and its conversion to database commands. I don’t think this is a major problem, but it does limit you to providers that handle LINQ. Here are some providers.
- Entity Framework (EF) is acknowledged as having the best LINQ-to-SQL conversion. EF currently only supports Microsoft SQL Server, although the EF v7 roadmap includes support for other database types.
- NHibernate, MySql and other database access providers support LINQ-to-database converter and supports a lot of database types. However I cannot vouch for the depth of their implementation.
- You can write your own LINQ data source provider already, and it is said to become easier in EF v7, which is out ‘soon’.
- LINQ/
IQueryableis not easily serialisable, so a system that has separated systems talking over some message bus would not work. However current scaling practice, see Azure’s How to Scale an Application, is to run multiple instances of the same application which works for this approach. - Some people say that passing
IQueryableright up to the Presentation Layer is an anti-pattern. The main concern is that used wrongly a developer can add a .ToList() to the end of a query and load thousands of rows of data. That is a concern, which is why I make the Presentation layer calls very simple and standard. My long term aim is to scaffold most of Presentation Layer, but I need to do more projects before I really know what is needed. - Similar to point 2 but in untrained hands software developers can write really bad queries that hit performance issues. This is true of nearly every ORM (Object-Relational Mapping) software system, but EF is big and it has taken me years to get really understand what EF is doing under the hood. However the fact is the software development part of a project is likely to be the biggest cost and a good ORM, training and a good SQL profiler is likely to reduce timescales.
Finally I should say that I describe a Layered Architecture but for really big systems this may not scale enough. However the overall approach of using LINQ and separating different parts of the processing of the query would be valid in other architectures like CQRS (Command and Query Responsibility Segregation) architecture or within each service in a MicroService architecture. I would recommend looking at the pdf of an excellent book called ‘Microsoft .NET: Architecting Applications for the Enterprise‘ for a detailed discussion of other approaches.
Conclusions
The aim of this project was to see if EF plus a range of open-source and proprietary libraries could do a good job of handling an existing database. In the first article I looked at the Data Layer and in this article I have described a software architecture that could a) provide a good the user experience, b) have a reasonable database performance and c) can be developed quickly.
I have found this project very revealing. Some things worked really well first time and some needed quite a bit of fiddling around. As a result of this I changed the implementation of some of my own libraries, like GenericServices, to better handle the new cases I encountered along the way. Overall I was pleased with how this project went: it only took two weeks, which is a lot faster than a project I did over a year ago where I hand coded the Data and Service Layers.
I hope this second article has given you some ideas on how EF and LINQ can be used to good effect throughout an application. I am not suggesting this is the only way to architect a system, but I think it is a useful approach to consider for small to medium sized systems, or subsystems, that use the .NET framework. For those who want to go beyond this I have given you references to places to research other approaches.
I have now set up a live web site running the web application that prompted this article. It is fairly basic in appearance as I was concentrating on the features, not the style, but you might find it interesting. I also have made the source code available on GitHub in case you might like to see how this application was built.
My open-source GenericServices library is now available on NuGet with documentation on the GenericServices’ GitHub Wiki.
=”margin-top:0cm;margin-right:1.0cm;margin-bottom:10.0pt;>
Load comments