This is the tenth installment of the TortoiseSVN and Subversion Cookbook series, a collection of practical recipes to help you navigate through the occasionally subtle complexities of source control with Subversion and its ubiquitous GUI front-end, TortoiseSVN. So far this series has covered:
- Part 1: Checkouts and commits in a multiple-user environment.
- Part 2: Adding, deleting, moving, and renaming files, plus filtering what you add.
- Part 3: Putting things in and taking things out of source control.
- Part 4: Sharing source-controlled libraries in other source-controlled projects.
- Part 5: Embedding revision details within your source files.
- Part 6: Working with tags and snapshots.
- Part 7: Managing revisions and working copies.
- Part 8: Getting the most from log messages.
- Part 9: Setting up a production server, browsing your repository, and viewing statistics on your installation.
Here, I’ll be describing how to go about extending source control, both in what is source-controlled and what tools you use to interact with it.
Reminder: Refer to the Subversion book and the TortoiseSVN book for further reading as needed, and as directed in the recipes below.
Source controlling your database
This is a strange concept the first time you consider it. Why on earth would you want your database in source control? How on earth is it possible to put gigabytes in source control? How does it mesh with your codebase?
You likely know the answer to the first question-why to put a database under source control-as soon as you pose it: for the same reason you put anything else in source control, to be able to revert to previous releases with minimal effort. Say for example, after you release version 1.0 of your product you put it in a new feature for version 2.0 that requires adding a couple new columns to a few tables and perhaps deleting a couple columns from some others. Once you make these changes to your database, then you can never revert to release 1.0 because the database is now broken from the perspective of the 1.0 codebase. In order to maintain the integrity of each revision in source control, you not only can but you must include your database schema in source control. So why put a database in source control? Because it is a crucial portion of your codebase.
As to how to put a database in source control, the point to realize is that you are not storing the data contained in the database only the structure of the data, i.e. the schema that describes the tables, triggers, views, etc. Your data does not belong in source control just like, for example, certain files in Visual Studio that store your personal preferences do not belong in source control. In the latter case, those settings belong exclusively to you. In the database case, whether you have 1000 records or 1001 records in your customer table does not have any bearing on the current revision of your software. That said, there is a useful exception to consider: static (or lookup or reference) data, i.e. data that is non-transactional that your application depends on. A simple example of this might be a table of US area codes, which went through a major “rewrite” a few years ago but before that they were probably invariant for fifty years or more. So it might be useful to have the data in this lookup table under source control because your code might actually be hard-coded for specific values.
To put a table in source control-or now more accurately you can say to put the schema for a table in source control-requires representing this schema in a textual form, i.e. the DDL code for the table. DDL can easily represent all your tables, views, indexes, triggers, etc. For the case of static data, here you need DDL to create the table and then DML-a series of literal INSERT statements-to populate the specific data values.
Applying Database Changes When Moving Among Revisions
Since both schema and data can be represented in code they can both be easily maintained under source control. But versioning the database code is only half the issue; you also have to materialize or reflect the structure and data represented by this code in your actual database. TortoiseSVN or Subversion (or indeed any source control system) is designed to handle the former but assuredly not the latter. One possibility is the manual approach: whenever you need to revert to a different revision, you first revert the code using TortoiseSVN/Subversion then you drop the changed tables and run the correct DDL to recreate them. Of course, draconian action like that has the unfortunate side effect of losing all your data!
A better approach, of course, is to use an application that integrates with Subversion to handle all the schema/data changes automatically. Likely there is more than one solution to the problem of source controlling a database but the one I am familiar with is SQL Source Control from Red Gate. (Full disclosure: Red Gate is the publisher of the Simple-Talk family of newsletters. But I do not work for Red Gate and the choice to recommend a Red Gate product is entirely my own because I happen to believe that Red Gate produces exceptionally fine tools for developers and DBAs.) The table below summarizes the manual approach vs. SQL Source Control in a nutshell. This is a condensation of the key points covered by David Duffett in his blog entry Database continuous integration and deployment with Red Gate tools.
| Old-School Approach | SQL Source Control from Red Gate |
| Shared database (“stepping on toes” of other developers) |
Private database (your breaking changes do not impact others) |
| Manually write change scripts for schema/data (did you put them in the right order?) |
Automatic change scripts generated (removes maintenance errors) |
| Manual deployment process (are you missing anything?) |
Automated deployment (alleviates major stress!) |
SQL Source Control Overview
SQL Source Control is not a standalone application; it integrates into SQL Server Management Studio and supports SQL Server 2005 or later. Red Gate provides an excellent introductory walk-through, including providing a script to create a dummy database, so I will not repeat it here. If you prefer video tutorial, Red Gate also provides a series of very short video overviews of key features of the product. I will just mention a few tidbits to conclude this recipe.
There are several ways to access SQL Source Control once you launch SSMS: select SQL Source Control from the Tools menu; select the Open icon at the top of the object explorer, or right-click an unlinked database in the object explorer and select Link Database to Source Control. (If you open the context menu on a linked database, you will have an assortment of SSC commands to pick from.) The act of opening SQL Source Control simply comprises opening another tab in SSMS alongside your query tabs; within this SQL Source Control tab are 4 sub-tabs (see Figure 10-1).
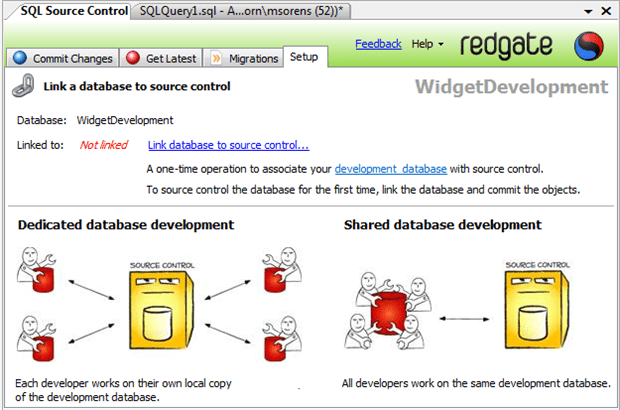
Figure 10-1 SQL Source Control’s initial display, showing 4 sub-tabs within its main tab.
The Setup sub-tab shown in the figure gives you an inkling as to the effort the Red Gate team put into optimizing the user experience. It succinctly and clearly lets you know the current state of things and what you need to do. For instance, linking to source control involves a crucial decision of whether you want a database exclusively for your use or whether you want to share a team database, so it devotes a considerable portion of the real estate to illustrating the difference. (Without SQL Source Control it would be cumbersome and time-consuming to provide private database copies. And, in fact, sometimes that is just what you need. But often a private database would allow all your team members to be more productive, and SQL Source Control provides that option.)
Just like TortoiseSVN provides a way to view source code differences among revision, SQL Source Control provides a similar user experience, showing differences in DDL when you make schema changes using any of the multiple methods provided by SSMS. Figure 10-2, borrowed from Red Gate’s walk through page, shows one such example where the datatype of one column has been changed.
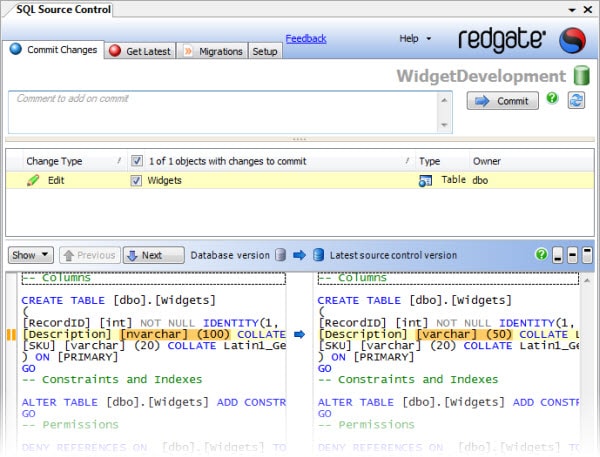
Figure 10-2 You can easily examine all your schema changes with the visual differencing tool within SQL Source Control’s Commit tab.
With SQL Source Control in place, there is no risk of Subversion getting in the way of productivity. Once you have made schema changes but have not yet committed them, you have only to select the object in the object explorer then select Undo Changes from its context menu to roll back to a clean state. Note, however, that there are several common changes that will not allow this: changes to static data, dropped data, and dropped columns that do not allow NULL values. See Undoing Changes for more details.
Other Considerations with SQL Source Control
The terminology used in context menus and elsewhere is typically different than you will see in TortoiseSVN’s context menus. The reason for that is that SQL Source Control is compatible with a number of source control systems (Subversion, Team Foundation Server, and Vault out of the box; others including Perforce, Git, and Mercurial with some configuration). The same issue applies to icon overlays, i.e. instead of a green check mark and red exclamation mark used by TortoiseSVN you get a blue or a red circle. It would be nice if one could specify the system (e.g. Subversion or Vault) and then SQL Source Control would use matching words and symbols.
The capability to change your world view from the latest version to an earlier version of your codebase is arguably the central tenet of source control systems. SQL Source Control provides this capability but it uses another Red Gate tool, SQL Compare, as its engine to do this. To be precise, SQL Source Control provides the connectivity between SQL Server Management Studio, your development database and your version control system, while SQL Compare provides the differencing and revisioning capabilities normally associated with a source control product. Most Red Gate customers using their SQL tools have the SQL Developer Bundle, which includes both SQL Source Control and SQL Compare, so it is not an issue. But for readers considering an individual purchase of SQL Source Control it is important to realize that SQL Compare is also needed. (Thanks to David Atkinson, product manager for SQL Source Control, for input on this.)
Readers of this series know that I devoted an entire chapter (Part 5) to the Subversion keyword feature. Alas, SQL Source Control does not support keyword expansion and in fact causes problems for any database files you have instrumented with keywords (commonly stored procedures). If, for example, you commit a file with an $Id$ place holder, the commit causes Subversion to update that with an appropriate value but SQL Source Control then considers that a change to the file. The only workaround at present is to remove the keyword place-holders from database files.
One aspect of SQL Source Control-indeed, many Red Gate products-that I think reflects the Red Gate team’s passion for excellence is their feedback forums. The SQL Source Control feedback forum lets users both post new suggestions and vote on existing ones providing the company with valuable intelligence not just qualitatively on what people would like to see but quantitatively by the number of votes. And they make it sublimely easy to do this-the Feedback link in Figure 10-1 takes you directly to the forum. As a couple examples, the lack of keyword support mentioned above is posted here and the terminology/icon issue is posted here.
Source controlling database objects is not without its difficulties. One example is that SQL Source Control would see a simple table rename as dropping one table and creating another (you could lose a lot of data this way!), described thorough by Mark Caldwell in this blog post. This was a significant issue until the advent of custom change scripts (also called migration scripts) in the recent 3.0 release. See Working with migration scripts for more on table renaming and a few other common issues.
Complementary Clients
Using Subversion within Visual Studio
For many source control operations, it does not really matter whether you integrate Subversion within Visual Studio. It merely provides a slight convenience factor by allowing you to, for instance, commit some changes within the Visual Studio window rather than having to click over to Explorer and commit from there using TortoiseSVN. But for some operations you get much more than trivial convenience. Consider the task of renaming a class. If you have ever tried to do this you already know that this is truly the proverbial chicken-and-egg dilemma. Do you rename your class in Visual Studio first then go back to Windows Explorer and correct all the adds/deletes that should really be renames? Or do you rename your class files in Windows Explorer then go clean up all the introduced compilation errors in Visual Studio? Kudos to the developers of TortoiseSVN for providing some support for the first approach-see the Renaming a file recipe in Part 2 of this series that explains how to repair a move from a disconnected add and delete pair. The second approach, though, is also viable because Visual Studio will certainly point you to just what broke and you can then walk through the list of errors and repair them. With Subversion integration in Visual Studio, on the other hand, renaming the class in Visual Studio’s solution explorer also performs the appropriate Subversion renaming in a single step!
The top contenders for Visual Studio integration seem to be AnkhSVN and VisualSVN. As to which of these is better, that question will likely not reach consensus anytime soon, judging from the online chatter. A good place to start is the StackOverflow question Which plugin do you use for SVN in Visual Studio? That post has links to other similar threads so there is an abundance of material to look through. Take care, though, since some parts of it are dated. You will, for instance, see a lot of comments about how buggy AnkhSVN was in version 1.x but now its version 2.x reincarnation makes it a viable contender. One usually great source for feature comparison among similar software tools is Wikipedia. See for example, their detailed comparison of source code control packages. Unfortunately, their comparison of Subversion clients offers very little information beyond platform and protocol on which to choose a product. But at least its list of available clients gives you a good place to start evaluating different clients.
The heart and soul of AnkhSVN is the powerful Pending Changes window in Visual Studio. Just like other real-time windows in Visual Studio that update as you type and perform actions to your code, this window updates in real-time to show you what files need to be committed and lets you enter a message and perform the commit. Figure 10-3 shows a screen shot of this from the AnkhSVN website.
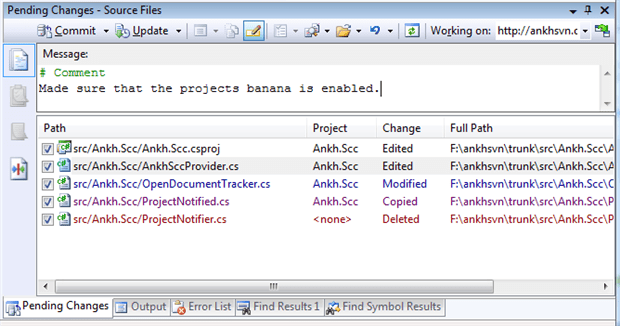
Figure 10-3 AnkhSVN’s Pending Changes window displays file changes within your solution in real-time. You can selectively pick those you want to commit, enter a commit message, and perform the commit right within the window.
I will just touch on one point that cropped up as I was researching these products. AnkhSVN could modify both solution files and project files. If some of your team members do not use AnkhSVN, these project file modifications cause annoying pop-ups; see this post. Subsequent messages in that conversation thread, however, indicate that you do not need the project file changes; the solution file change will suffice and that will be transparent to non-AnkhSVN users. Yet farther down, another post in the thread indicates you do not even need to touch the solution file if you select the source control provider before you load your solution. You do that from the Visual Studio Tools >> Options menu as shown in Figure 10-4.
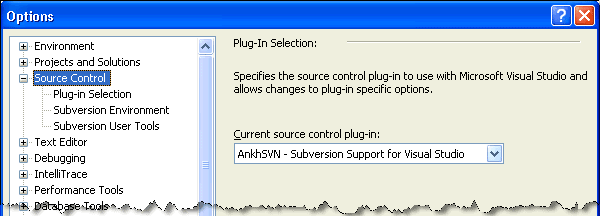
Figure 10-4 Select the source control provider for AnkhSVN from Visual Studio’s Options window before you load your solution and AnkhSVN does not need to adulterate either your solution file or project files.
VisualSVN is another option for Visual Studio integration. VisualSVN leverages TortoiseSVN functionality using many of the same dialogs. If you are reading this you likely have TortoiseSVN installed so that saves a bit on learning a new toolset.
Worth an honorable mention is the eponymous Visual Studio File Explorer Add-in from Mindscape that, well, provides a standard file explorer within Visual Studio that is shell-enabled, thus shell extensions-such as TortoiseSVN-work inside Visual Studio. The screenshots on Mindscape’s web site show you at a glance what you get: a dockable tree navigator, a dockable split pane with tree and file list, or a full Visual Studio tab with split pane. (Thanks to Brann on the StackOverflow post Which plugin do you use for SVN in Visual Studio? for making me aware of this.)
Using Subversion with your database within Visual Studio
A complementary product to Red Gate’s SQL Source Control is (currently) titled SQL Connect, a Visual Studio extension. Once installed, you have templates to create a database project that gives you functionality very similar to SQL Server Management Studio, all within Visual Studio. In addition, SQL Connect integrates with SQL Source Control and your version control system (in this case Subversion) to allow you to properly version everything relevant in your project. When you start SQL Connect from within Visual Studio, you get a clean and clear user experience. The first dialog directs you to choose between a new database project vs. importing one from SQL Source Control. If the latter, you merely have to indicate a path to the working copy of your database project, then synchronize the actual database to the Visual Studio database project (Figure 10-5).
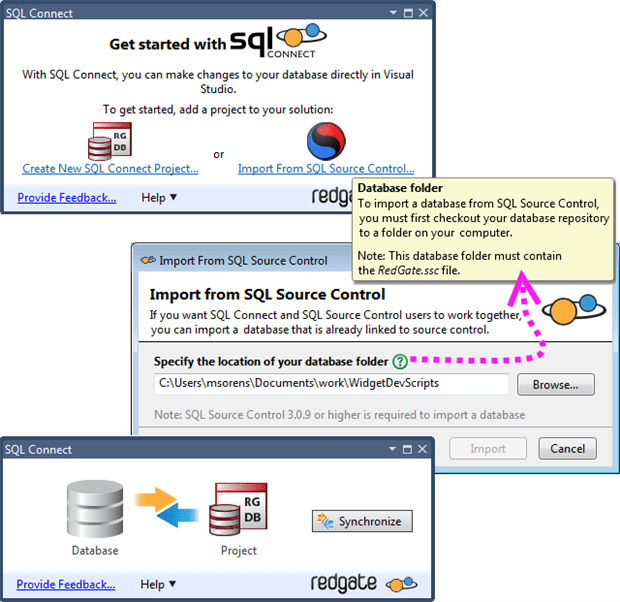
Figure 10-5 SQL Connect is remarkably simple to set up allowing you to either create a new database project in Visual Studio or import one (top). For the latter case, you merely point to the existing project (middle) and synchronize the actual database to the project (bottom).
Using Subversion within Eclipse
Another offering from Collabnet, Subclipse allows you to use Subversion within Eclipse for your Java-based projects. The screenshots section at the link above give you a good overview of what Subclipse in action looks like, so I will not repeat it here. Also browse the Subclipse documentation. One point worth mentioning, however is that the revision graph feature in Subclipse displays merges, something TortoiseSVN does not do. (See this StackOverflow post for discussion on this point with regard to TortoiseSVN.)
Using Multiple Subversion clients together
You and your team members are free to use different clients-or different versions of the same client-to access your Subversion repository. That innocuous statement is fairly remarkable. Consider the same claim in the context of, say, word processors: “you are free to use different word processors to edit a particular file”. Perhaps Word, WordPerfect, WordPad, OpenOffice Write, and GoogleDocs. Well, yes, you could edit the file, but would it maintain integrity by hopping around between these various editors? Not likely! To be fair this is not really an apples-to-apples comparison. With Subversion clients, after all, we are talking about clients that all communicate with a central server. But source control software, as you may have gathered by reading this series or other references, is a complicated, subtle beast. So it is indeed remarkable that you can use different Subversion clients interchangeably to connect to your Subversion server. This is the epitome of good design in that things just work the way they should. Asking the question of whether members of a team can use different Subversion clients is “…a lot like asking if it’s ok for your website users to use Safari and Firefox.” (Thanks to Rein Henrichs on this question on StackOverflow for that great analogy!)
The caveat, however, is that they all must be compatible with each other. And that is typically a lot easier to do than it sounds. According to the TortoiseSVN FAQ:
…you can only use different clients if they all use the same version of the Subversion library. The version of the Subversion library that TortoiseSVN uses is indicated in the filename of the installer, other clients have similar indications. You have to make sure that those versions match each other in the first two digits. For example, all clients using Subversion 1.6.x can be used together (the ‘x’ indicates that this number is not relevant for compatibility).
In this example, any other clients that also use the 1.6 version of the underlying Subversion library may be freely used interchangeably. Furthermore, as pointed out by Greg Hewgill in this question on StackOverflow, this is really referring to having multiple clients operating on the same working copy, i.e. the same physical directories on your machine. Hewgill explains further that the server is much more forgiving, implying that a coworker, having a separate working copy on a different machine, could even use a client with a different main version number without causing any incompatibility issues. But back to the first point: you can run multiple clients on your machine on the same working client. If you have been reading sequentially you have already seen an example of why you might want to do this: running TortoiseSVN for access from Windows Explorer and running AnkhSVN for access from within Visual Studio.
Subversion and TortoiseSVN both recently had a 1.7 release. Normally this means, per the rules I’ve described, that 1.7 servers and clients cannot mix with 1.6 servers and clients. But in this particular instance the repository format did not change from 1.6 to 1.7. It is, according to the 1.7 release notes, “possible to seamlessly upgrade and downgrade between 1.6.x and 1.7.x servers without changing the format of the on-disk repositories.” Clients, on the other hand, have a new working copy format. That means you cannot use 1.6 clients on 1.7 working copies, of course, but it also means you cannot use 1.7 clients on 1.6 working copies-until you upgrade the working copy from the TortoiseSVN context menu.
Load comments